 성빈|Apr 24, 2023
성빈|Apr 24, 2023
스퀘어랩에서는 각 microservice 별로 발생하는 로그들을 logstash를 활용하여 수집하고 있습니다. 이 과정에서 쌓이게 되는 수많은 로그들을 관리하는 비용을 줄이고, 서비스 모니터링과 로그 관리를 더욱 편리하게 할 수 있다는 기대를 갖고 Datadog을 적용해보는 PoC 기간을 갖게 되었습니다. 이 글은 Datadog 연동에 대한 관심이 있으신 분들에게 도움이 될 것 같습니다.
Datadog 적용 과정
K8s 클러스터에 Datadog을 적용하는 과정은 다음과 같이 세 단계로 요약할 수 있습니다. Helm chart install → Deployment tagging / 환경변수 주입 → 재배포
prd 환경에 적용하기 위한 준비 단계로, 먼저 dev 환경에 Datadog을 적용해보았습니다.
dev와 prd cluster에서 각각 values-dev.yaml / values-prd.yaml 를 사용하도록 했습니다.
Datadog helm chart Install
helm install이 성공적으로 마무리 되면, datadog-cluster 가 생성되고, k8s cluster의 각 노드별로 Datadog agent pod이 하나씩 생성되게 됩니다.
여기에서 values.yaml의 default 값을 참고하여, 필요한 부분만 골라서 yaml 파일을 작성했습니다.
처음 적용 과정에서 어떤 옵션이 필요한지 판단하기가 어려워 많은 시행착오를 거쳤고, 이 과정에서 겪은 시행착오들과, 처음 Datadog을 적용해보려는 분들에게 도움이 될 만한 내용들을 소개해드리겠습니다.
1. Agent version 불일치
처음에는 values.yaml 파일 내에 clusterName 등 필수 값과 사용할 기능들을 enable: true로 설정한 후, Datadog으로부터 발급받은 apiKey와 함께 helm install 을 진행했습니다.
이 때 아래와 같은 error가 발생했습니다.
Error: INSTALLATION FAILED: execution error at (datadog/templates/_helpers.tpl:17:4): This version of the chart requires an agent image 7.36.0 or greater. If you want to force and skip this check, use `--set agents.image.doNotCheckTag=true`
당시 values.yaml 내에 tag 를 설정해주지 않아서 발생했던 문제였습니다.
clusterAgent.image.tag / agents.image.tag / clusterChecksRunner.image.tags 에 동일한 값을 입력하여 해결했습니다.
2. env 주입 / labelling
Connecting Node.js Logs and Traces Configuring the Node.js Tracing Library
- 각 서비스별로
DD_LOGS_INJECTION환경변수가 주입되면 Datadog은 console로 print 되는 로그들을 자동으로 수집합니다. - 별도의 설정 없이도 서비스의 env, service, version을 자동으로 발견합니다.
Node의 경우에는
package.json내에 있는 값을 참고하게 되는데, 이 값을package.json에서 관리할 수도 있지만,env의 경우는 cluster마다(또는 namespace마다)version의 경우에는 deployment가 배포될 때마다 변경되어야하므로 서비스별 yaml 파일의 metadata 부분에 값을 지정해서 관리하는 것이 편리했습니다. - annotations 에서 JS 서비스인지, Java 서비스인지에 알맞게 library를 지정해주었습니다.
해당 서비스의 yaml 파일이 수정되었을 때, deployment를 재시작하여 반영상태를 확인할 수 있는데, 이 때 각 pod의
datadog-lib-initcontainer가 정상적으로 실행/종료 되었어야합니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-name
labels:
...
tags.datadoghq.com/env: ${ENV} # dev | qa | rc | prd
tags.datadoghq.com/service: service-name
tags.datadoghq.com/version: ${VERSION}
spec:
...
template:
metadata:
annotations:
...
admission.datadoghq.com/js-lib.version: v0.00.0
# or admission.datadoghq.com/java-lib.version: v0.00.0
spec:
containers:
- name: service-name
...
env:
...
- name: DD_LOGS_INJECTION
value: 'true'
3. 불필요한 log들을 indexing 대상에서 제외하기
health check 와 같이 주기적으로 호출되는 log들은 status level이 info가 아닐 경우에만 수집하도록 indexing 대상에서 제외하면 요금을 절약할 수 있습니다.
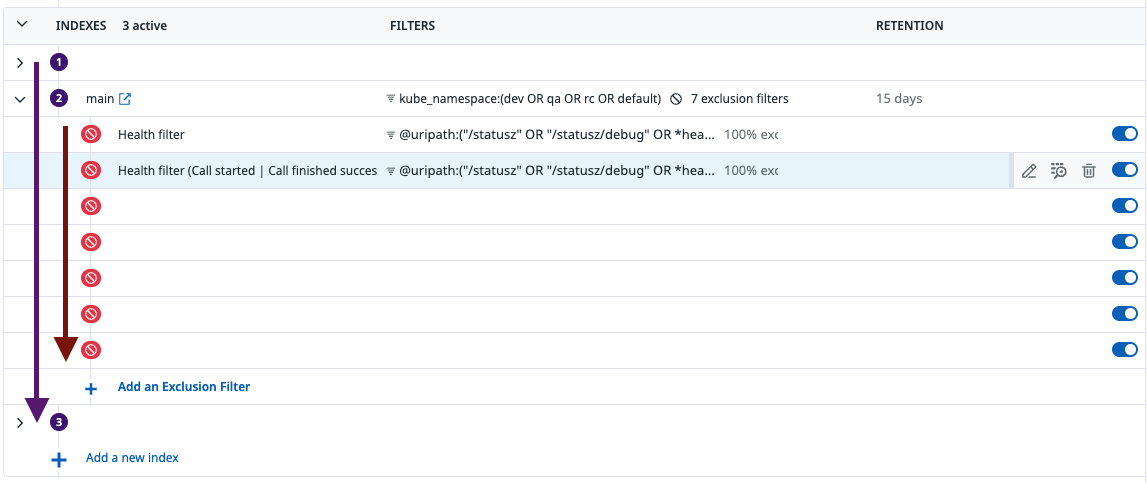 위 이미지는 Logs - Configuration - Indexes에서 kube_namespace가 dev / qa / rc / default(prd) 일 때 health check filtering 하는 부분만 나타냈습니다. 위와 같이 사진과 같이 필터를 적용할 수 있습니다. 필터는 상단에서 하단부로 내려가면서 차례대로 적용되며, 한번 filter 된 Log는 하위 필터에서 발견되지 않습니다. 그래서 상위 필터에서 너무 범용적인 조건을 걸면 하위 필터에서 해당 내용을 처리할 수가 없습니다.
위 이미지는 Logs - Configuration - Indexes에서 kube_namespace가 dev / qa / rc / default(prd) 일 때 health check filtering 하는 부분만 나타냈습니다. 위와 같이 사진과 같이 필터를 적용할 수 있습니다. 필터는 상단에서 하단부로 내려가면서 차례대로 적용되며, 한번 filter 된 Log는 하위 필터에서 발견되지 않습니다. 그래서 상위 필터에서 너무 범용적인 조건을 걸면 하위 필터에서 해당 내용을 처리할 수가 없습니다.
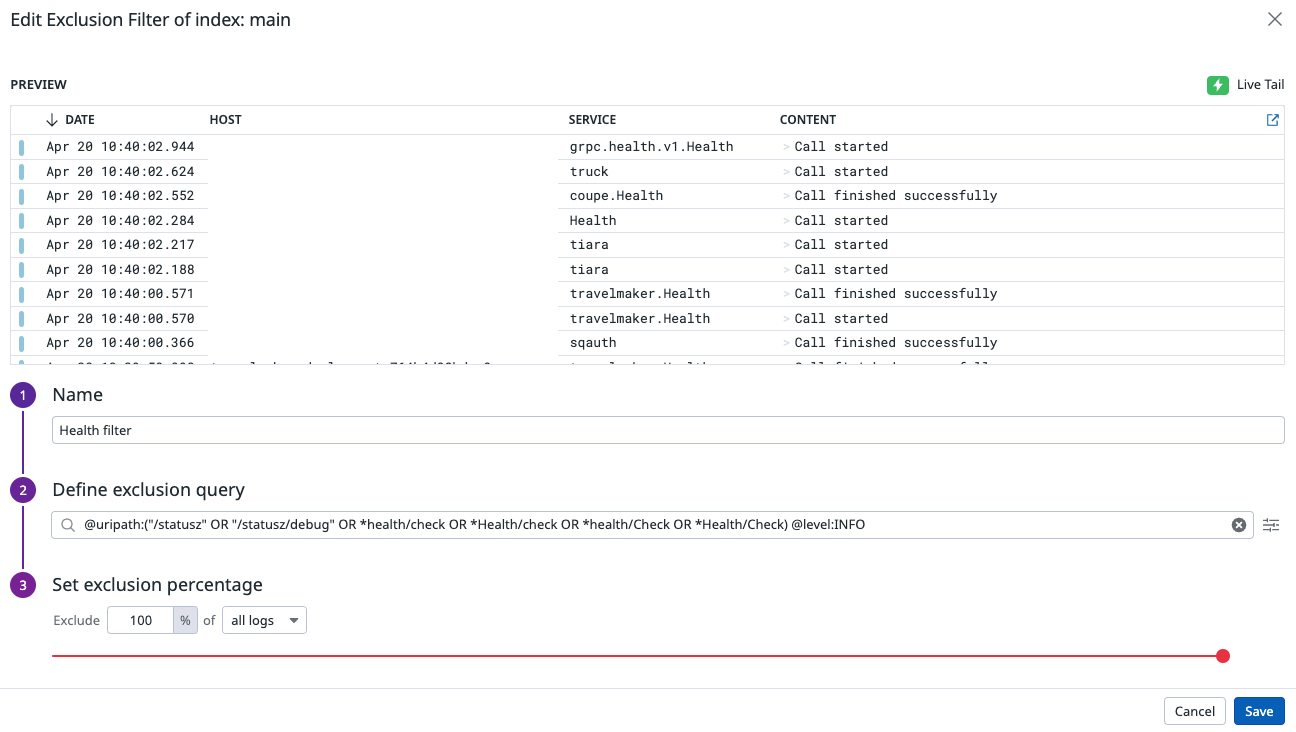 이 때, Exclusion Filter에서는 해당 필터 조건에 맞는 로그들을 제외시키기 때문에 execlusion operator(
이 때, Exclusion Filter에서는 해당 필터 조건에 맞는 로그들을 제외시키기 때문에 execlusion operator(-)를 사용하면 오히려 indexing 대상이 됩니다. Datadog에서는 case sensitive 하게 query 하기 때문에, 위 이미지의 exclusion query 부분에서 확인할 수 있듯, uripath가 health/Check 와 Health/check 인 경우를 모두 고려할 수 있어야했습니다. * 를 사용해서 일부분을 matching 시킬 수는 있지만, 정규식의 case insensitive 옵션을 주듯이 할 수는 없었습니다. 위의 exclusion query에서 health check filtering 부분은 ? 를 사용하여 조건을 *?ealth/?heck 와 같이 설정할 수도 있겠지만, 추후에 알아보기가 어려울 수 있을 것 같아 각각의 case를 모두 설정해주었습니다. *[hH]ealth/[cC]heck 와 같은 형태의 정규식으로 검색할 수 있으면 좋겠지만, 아쉽게도 search query 내부에서는 이런 정규식이 허용되지 않습니다.
Logs - Search에서는 여기서 설정한 index 그룹별로 로그를 확인할 수 있습니다.
4. Log pipeline
Datadog은 기본적으로 console에 출력되는 로그를 그대로 가져옵니다. 기존에 Filebeat에서 사용하던 규칙을 그대로 datadog pipeline으로 옮기기 위해서는, 로그내의 정보를 조합해서 새로운 attribute를 만들거나, JSON 형식이 아닌 로그에 대해서는 parser 적용 ➡️ remapper 적용 과정이 필요했습니다.
-
서비스별로 사용하고 있는 logger의 종류에 따라 아래와 같이 remapper를 다르게 설정해주어야했습니다.
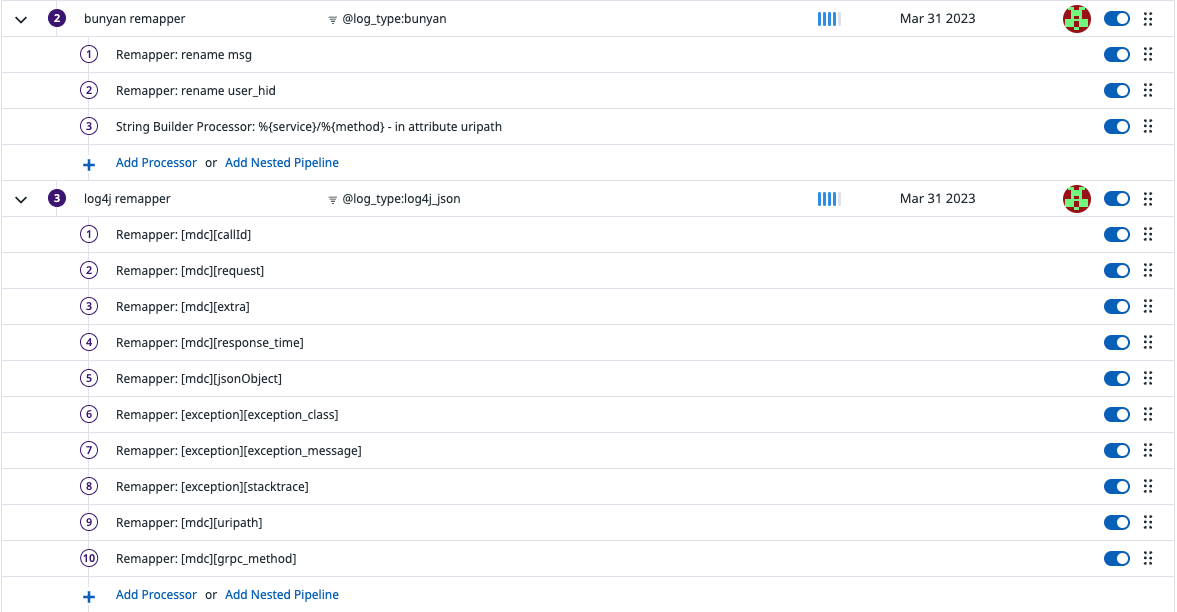
- 로그의 date가 Datadog에서 처리된 시점으로 기록되어서, 적절한 시간대가 기록되지 않고 순서가 엉키는 경우가 있었습니다.
Date Remapper를 사용해서 해당 로그에 기록되어있는 시간을 date로 사용하도록 했습니다. - 내부적으로 사용하고 있는
grpc status code를 Datadog에서 처리할 수 있는 level(INFO/WARN/ERROR)로 변형시키기 위해서Lookup Processor➡️Status Remapper를 적용했습니다. - JSON 형태가 아니라, string으로 출력되는 로그의 경우 Level이
INFO또는WARN이어야하지만ERROR로 설정되거나 또는 그 반대로 적용되는 경우가 있었습니다. 이 때는Grok Parser➡️Status Remapper를 적용했습니다. 아래 이미지는 error level 조정 전에INFO여야할 log들이ERROR로 처리되다가 Remapping 적용 후 정상적으로 처리되고 있는 모습입니다.
모든 로그를 이렇게 UI 상에서 필터링 해야하는 것은 아닙니다. yaml 파일 내부에 exclude_at_match 또는 include_at_match 에 정규식 패턴을 작성하여 Datadog으로 전송되지 않도록 global processing rule을 적용할 수 있습니다.
다만, json 형태의 로그에서 정규식으로 다양한 AND / OR 조건을 거는 것은 경제적이지 못하고, Datadog에서도 저장되는 로그의 양으로 비용을 계산하기 때문에 UI 상에서 pipeline과 filtering 조건을 거는 것이 낫겠다고 판단했습니다.
5. APM tracing 대상에서 제외하기
Health check 와 같은 내용들은 로그 indexing은 해야하지만, trace 대상에서는 제외하는 것이 맞게다고 판단하여 resource를 기준으로 완전히 제외했습니다.
datadog:
...
agents:
...
containers:
traceAgent:
env:
- name: DD_APM_IGNORE_RESOURCES
value: (?i)grpc\\.health\\.v1\\.Health\\/Check$
DD_APM_FILTER_TAGS_REQUIRE / DD_APM_FILTER_TAGS_REJECT 환경변수를 부여해서 apm 대상에서 포함하거나 제외할 수 있습니다. 하지만, 각 조건들은 OR로 묶이고 정규식을 지원하지 않습니다.
DD_APM_IGNORE_RESOURCES 환경변수는 resource를 기준으로 정규식을 적용할 수 있어서 Health check 대상에서 위와 같이 제외했습니다.
6. secretBackend
k8s deployment yaml 파일을 작성하듯, Datadog helm chart를 install 할 때에도 클러스터에 입력되어있는 secret 값을 참고하고 싶었습니다. 이를 위해 Datadog에서는 secretBackend를 제공합니다.
Datadog apiKey 의 경우, helm chart install / upgrade 시 매번 입력하거나 해당 값을 그대로 파일 내에 입력해놓기보다는 secret 값을 참조하도록 하면 안전하게 값을 관리할 수 있겠습니다.
아래와 같이 secret을 생성했다면,
kubectl create secret generic datadog-secret --from-literal api-key="api key from datadog"
values-dev.yaml 에서는 아래와 같이 secretBackend command를 설정해주어야하며, 이로 인해 ENC 태그로 둘러쌓여있는 부분이 변환 될 수 있습니다.
datadog:
apiKey: ENC[k8s_secret@dev/datadog-secret/api-key]
secretBackend:
command: '/readsecret_multiple_providers.sh'
7. DB Monitoring
Setting Up Database Monitoring for Amazon RDS managed MySQL Amazon RDS DB 인스턴스 수정
DB Monitoring을 적용할 때에도, ENC를 사용하여 secret 을 참조하도록 작성했습니다.
datadog:
...
clusterAgent:
...
confd:
mysql.yaml: |-
cluster_check: true
init_config:
instances:
- dbm: true
host: ENC[k8s_secret@namespace/dbm-cred/host]
port: ENC[k8s_secret@namespace/dbm-cred/port]
username: ENC[k8s_secret@namespace/dbm-cred/username]
password: ENC[k8s_secret@namespace/dbm-cred/password]
DBM 설정 과정은 다음과 같습니다. DB parameter 설정 ➡️ datadog 계정 생성 / 권한 부여 ➡️ Agent 설치 ➡️ (optional) Datadog RDS Integration
Datadog 계정을 생성하고, Agent 설치까지 완료했으나, DB Monitoring이 활성화되지 않는 이슈가 있었습니다. agent 내에 dbm 설정이 제대로 되어있는지 확인하기 위해서는, node 별로 생성된 datadog-agent pod들 중 하나에서 agent check mysql 를 실행해보는 것이 필요했습니다. 이 때 해당 명령어로 확인할 수 있는 pod은 랜덤으로 지정되어서 불편한 점이 있었습니다.
agent check mysql 을 실행해보니 아래와 같은 Warning이 확인되었습니다.
=========
Collector
=========
Running Checks
==============
mysql (x.x.x)
--------------
Instance ID: mysql:xxx [WARNING]
Configuration Source: file:/etc/xxx/conf.d/mysql.yaml
Total Runs: 1
Metric Samples: Last Run: 88, Total: 88
Events: Last Run: 0, Total: 0
Service Checks: Last Run: 3, Total: 3
Average Execution Time : 97ms
Last Execution Date : 2023-03-30 06:47:33 UTC (1680158853000)
Last Successful Execution Date : 2023-03-30 06:47:33 UTC (1680158853000)
Warning: Unable to collect statement metrics because the performance schema is disabled. See <https://docs.datadoghq.com/database_monitoring/setup_mysql/troubleshooting#performance-schema-not-enabled> for more details
code=performance-schema-not-enabled host=<RDS_HOST>
Warning: Query activity and wait event collection is disabled on this host. To enable it, the setup consumer `performance-schema-consumer-events-waits-current` must be enabled on the MySQL server. Please refer to the troubleshooting documentation: <https://docs.datadoghq.com/database_monitoring/setup_mysql/troubleshooting#events-waits-current-not-enabled>
code=events-waits-current-not-enabled host=<RDS_HOST>
문제는 DB parameter가 RDS 상에서 default mysql 값으로 지정되어있다보니, performance_schema 값이 0으로 되어있던 것이었습니다. max_digest_length / performance_schema_max_diget_length / performance_schema_max_sql_text_length 값들도 4096 으로 설정이 필요했습니다. 이후 파라미터 그룹을 적용하기 위해서는 DB를 수동으로 재시작해야 했습니다.
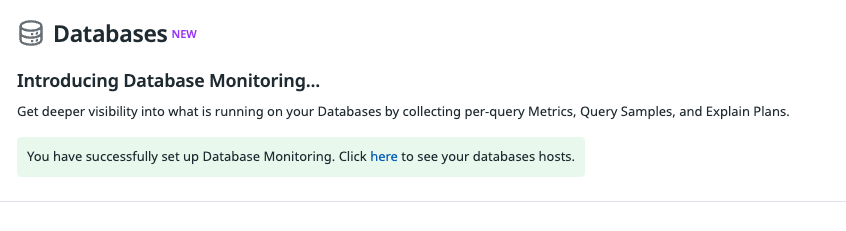 DB를 재시작 하고 난 뒤, Database Monitoring이 성공적으로 set up 되었다는 기쁜 메시지를 확인할 수 있었습니다.
DB를 재시작 하고 난 뒤, Database Monitoring이 성공적으로 set up 되었다는 기쁜 메시지를 확인할 수 있었습니다.
8. Kotlin 서비스의 일부가 APM catalog 목록에 뜨지 않는 경우
Kotlin으로 작성한 프로젝트들 중 일부는 APM 목록에서 확인할 수가 없었고, 해당 에러는 socket 경로를 찾지 못했다는 것이었습니다.
 그러나 pod에 직접 접속하여 해당 경로를 확인해보면,
그러나 pod에 직접 접속하여 해당 경로를 확인해보면, dsd.socket 은 해당 경로에 존재하고 있었습니다.
문제가 되는 서비스들의 환경변수에 아래와 같이 DD_DOGSTATSD_SOCKET 을 추가해주었습니다.
- name: DD_DOGSTATSD_SOCKET
value: '/var/run/datadog/dsd.socket'
그 후, pod을 재시작했을 때는 아래와 같이 dsd.socket 을 Detect 했다는 로그를 확인할 수 있고, 해당 서비스를 APM 목록에서 확인할 수 있었습니다.

즉, socket 경로를 찾지 못해서 발생하는 버그로 판단됩니다.
9. Trace ID가 제대로 연결되지 않음
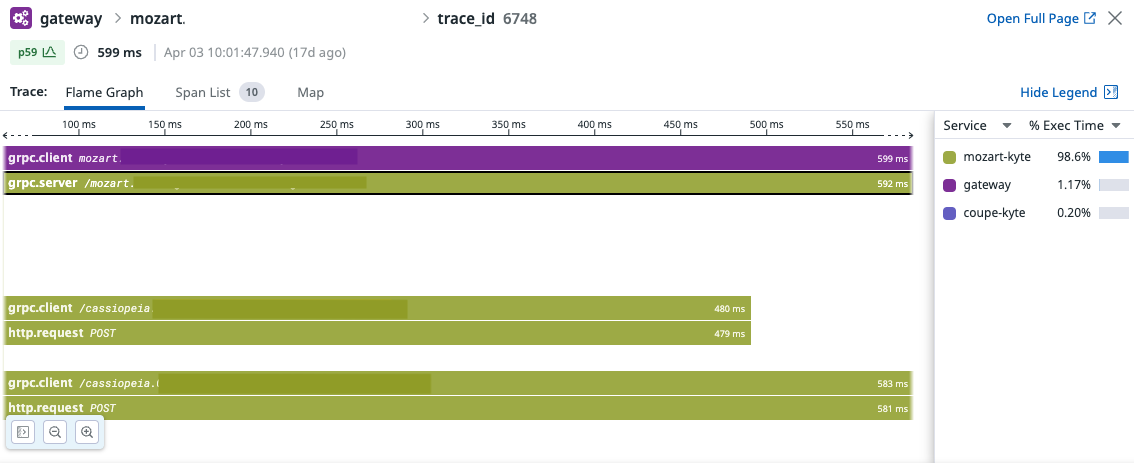
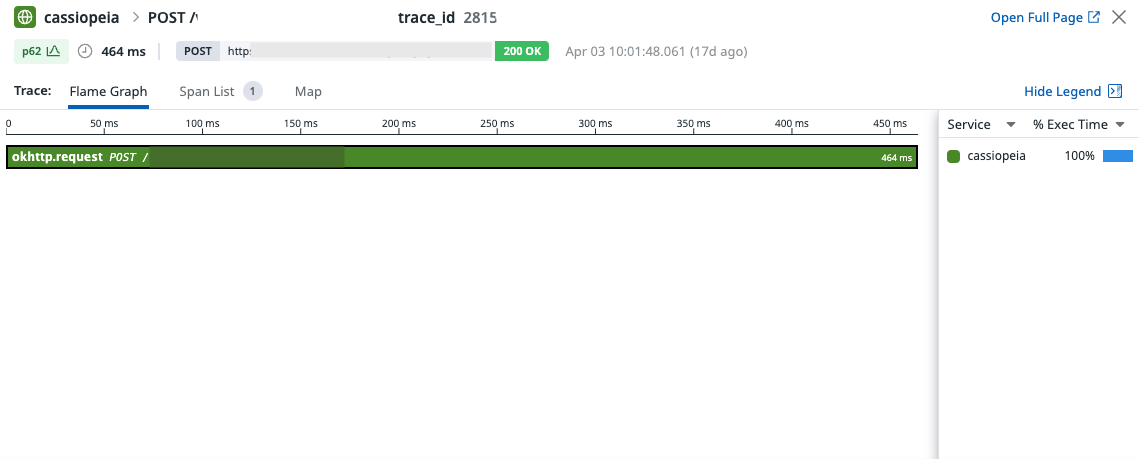 Node.JS 서비스들에서는 잘 작동하지만, Node ➡️ Kotlin 프로젝트로 grpc request 가 진행될 때,
Node.JS 서비스들에서는 잘 작동하지만, Node ➡️ Kotlin 프로젝트로 grpc request 가 진행될 때, trace id 가 이어지지 않고 새로운 trace_id가 부여되어서 별도의 span이 생기는 경우가 있었습니다.
기존에는 logging시 header에 request_id 정보가 있으면 해당 request_id 를 다음 request로 가져가고, 해당 정보가 없으면 새롭게 발급하여 log들 간 tracing을 하고 있었습니다.
APM trace 기능이 제대로 동작한다면, 편리하게 확인할 수 있는 상황이었기에, Log Pipeline에서 Trace ID Remapper 를 사용하면 간단하게 적용될 것으로 예상했었습니다.
그러나 Remapper를 적용하면 Log - Search에서는 trace_id attribute가 request_id로 변경된 것을 확인할 수 있지만, APM에서는 trace_id 가 그대로 64 bits unsigned int 형태로 존재했습니다.
Java 계열의 서비스는 mdc 내부에 dd.trace_id 가 주입되고 있어서 Log - Configuration의 Preprocessing for JSON logs 단계에서 Trace Id attributes 설정에 mdc.dd.trace_id 를 추가해야했습니다.
Datadog 측으로부터 현재 Node.JS와 Kotlin의 Framework를 아직 지원하고 있지 않기 때문에 auto instrumentation이 제대로 적용되지 않는 현상으로 확인하였고, 코드 단에서 header 정보를 Node.JS에서 추출하여 Kotlin(Java)로 주입하는 방법을 안내받았습니다.
Datadog java trace GitHub repository에서 잦은 release가 일어나고 있습니다. 어쩌면 코드 내부로 tracing관련 코드를 가져오는 것 보다는 auto instrumentation이 잘 작동하기를 기다리거나 해당 Repository에 직접 기여하는 것이 나을 수도 있겠습니다.
마무리
Datadog helm chart install시의 설정만 제대로 해준다면, k8s 환경에서 Datadog을 적용하는 것은 꽤나 편리했습니다. 기존에 logstash상에서 로그를 검색하면서 겪었던 불편함은 Datadog을 사용하면서 어느정도 해소될 수 있었습니다. 서비스별 monitor나 dashboard도 확인하기 편리하여, 트래픽이 몰리는 시점에 대비하여 deployment의 scale out을 진행할 때 모니터링 하기에도 유용했습니다. 비용과 사용성을 고려하여 dev cluster에서는 log indexing기능만 사용하고, prd에서는 APM이나 DB monitoring까지 적용해서 사용한다면 훨씬 경제적으로 log를 관리할 수 있을 것으로 기대됩니다.
마지막으로, PoC 기간 동안 많은 도움 주신 데이터독 관계자 분들과 메가존 기술팀 분들께 감사드립니다! 🙇♂️