 권영재|Jan 24, 2024
권영재|Jan 24, 2024
카이트에서는 사용자에게 출/도착 날짜별 최저가를 시각적으로 한눈에 보여주기위해 아래처럼 항공 캘린더 기능을 제공합니다. 이 기능이 어떻게 구현된 것인지 궁금하지 않으신가요?

대부분의 항공권 검색 엔진의 경우 특정 날짜를 선택해야만 항공권의 가격 조회를 할 수 있도록 되어있습니다. 하지만 이 방식으로는 사용자에게 여러 출/도착 날짜별 최저가를 보여주려면 한 목적지에 대해 수천번의 가격 조회를 한번에 수행해야 하기 때문에 시간이 너무 오래 걸리다보니 해당 기능을 제대로 제공할 수가 없습니다. (국제선 왕복 항공권의 경우 보통 가는편, 오는편의 가격이 별도로 책정되어있지 않고 출발일-도착일로 묶인 상태로 가격이 책정되어있습니다. 때문에 하나의 목적지에 대해 현재 날짜로부터 100일 동안, 각 출발일로부터 여행 기간이 1일~14일 사이의 가격을 조회하려면 100 x 14 = 총 1400개의 조합이 생겨나게 됩니다)
때문에 카이트에는 사용자가 조회하기 전에 미리 여러 목적지에 대해 날짜별로 가격 조회를 수행한 결과를 자체 저장소에 데이터를 저장해둔 후, 이 데이터를 기반으로 날짜별 최저가를 빠르게 조회할 수 있도록 하고있습니다.
데이터 파이프라인 소개
앞서 설명했던 기능이 실제로 어떻게 구현되었는지 데이터 파이프라인에 대해 조금 더 자세히 설명하자면 다음과 같습니다.
- 항공권 검색엔진에서 가격 조회를 수행하여 조회된 내용을 AWS S3에
json형태로 저장 (이후로는fare_crawler라고 부르겠습니다.) - AWS S3로 부터 저장된 데이터를 읽어와서 적절한 형태로 가공하여 데이터 저장소(Elasticsearch)에 저장 (이후로는
fare_updater라고 부르겠습니다.) - 앱에서 API를 호출하면 데이터 저장소로 부터 날짜별 최저가 데이터를 한번에 조회하여 응답
여기서 1, 2번 과정의 경우 하루에 한번 사용자 트래픽이 적은 새벽시간에 수행되도록 스케쥴링 되어있습니다.
1, 2번 단계를 하나로 어플리케이션으로 합칠수도 있지만 굳이 분리해둔 이유는 다음과 같습니다.
- 재시도 기능
fare_crawler와fare_updater각 작업을 개별 재시도 가능하게 만들기 위함입니다.fare_crawler에서 항공권 검색엔진에 대해 API 호출 한도(rate limit)를 넘기지 않고 수천~수만번의 가격 조회 요청을 수행하다보면 시간이 꽤나 많이 소요됩니다. 때문에 작업을 수행하는 도중에 오류가 발생하여 어플리케이션이 종료되면, 오류가 발생한 지점부터 이어서 진행하는 기능이 필수적입니다.
- 병렬 처리 기능
fare_crawler의 가격 수집 처리 속도 혹은fare_updater가 수집된 가격을 읽어와서 저장소에 저장하는 속도를 빠르게 하기 위해 작업별로 샤딩(sharding)하여 병렬 처리를 수행하기위하여 필요합니다.- 두 작업의 경우 특성도 다르고 수행에 소요되는 시간도 다르기 때문에 각 어플리케이션의 상황에 따라 다른 샤드(shard) 갯수를 적용하여 최적화하면 목표 시간내에 작업을 더 효율적으로 완료할 수 있습니다.
이렇게 구성된 데이터 파이프라인은 쿠버네티스 클러스터에서 Argo Events를 통해서 미리 정의된 Argo Workflow를 트리거하여 작업을 수행하게 됩니다.
다음 섹션에서는 Argo Events와 Argo Workflow에 대해 간단히 소개하면서 실제로 어떻게 적용되어있는지 예시와 함께 설명해보도록 하겠습니다.
Argo Workflow/Events 를 이용한 데이터 파이프라인 구성
최저가 운임을 조회하여 저장하는 파이프라인은 쿠버네티스 클러스터 상에서 Argo Workflow와 Argo Event를 를 통해 구성되어있습니다.
Argo Workflow 소개
Argo Workflow 는 쿠버네티스 클러스터 상에서 컨테이너 기반의 워크플로우를 정의하고 실행하기 위한 오픈 소스 플랫폼입니다. 이를 통해 사용자는 복잡한 작업과 데이터 처리 플로우를 효율적으로 관리하고, 자동화할 수 있습니다. Argo Workflow는 각 단계를 컨테이너로 캡슐화하여 실행하며, 이들 간의 의존성과 순서를 정의할 수 있습니다. 이를 통해서 병렬 처리와 조건부 실행, 반복 실행 등의 기능을 제공하기 때문에 쿠버네티스의 자원을 효율적으로 활용하는데 도움이 됩니다.
비슷하게 데이터 처리하는 Job을 수행할 수 있는 Spring Batch 같은 도구가 존재하지만, Spring Batch에서는 어플리케이션이 실행되는 서버 인스턴스 리소스의 최대치가 데이터 처리 작업을 수행하는데 사용할 수 있는 리소스의 최대치와 동일하기 때문에 클라우드 환경에서 분산처리나 병렬처리 작업에 한계가 있을 수 있습니다.
하지만 Argo Workflow를 사용하면 쿠버네티스를 통해 효율적으로 사용가능한 자원을 할당받아 사용할 수 있습니다. 필요한 자원이 부족하면 클러스터 오토스케일러에 의해 클러스터 노드가 자동으로 늘어나기 때문에 필요한 자원을 더 사용할 수 있게 됩니다. 반대로 작업이 종료된 후에는 클러스터 오토스케일러를 통해 노드가 자동으로 줄어들면서, 불필요한 유휴 자원으로 인해 비용을 더 사용하는 것을 절약 할 수 있게됩니다.
Argo Workflow를 쿠버네티스 클러스터에 설치한 후에 Workflow 스펙을 yaml로 작성하여 적용하면 미리 도커 이미지로 빌드해둔 fare_crawler 또는 fare_updater 어플리케이션을 쿠버네티스 클러스터 상에서 수행할 수 있게됩니다. 또한 Argo Workflow 대시보드 혹은 CLI를 통해서 현재 수행중인 Workflow의 상태 또는 완료된 Workflow의 결과 등을 손쉽게 확인할 수 있고, 수동으로 트리거하는 것도 가능합니다. Cron Workflow를 이용하면 Workflow가 주기적으로 실행되도록 설정하는 것도 어렵지 않게 할 수 있습니다.
Argo Events 소개
Argo Events는 여러가지 이벤트 소스들로부터 발생하는 이벤트를 모니터링하고있다가 해당 이벤트에 연결된 동작을 트리거 해주는 기능을 제공합니다.
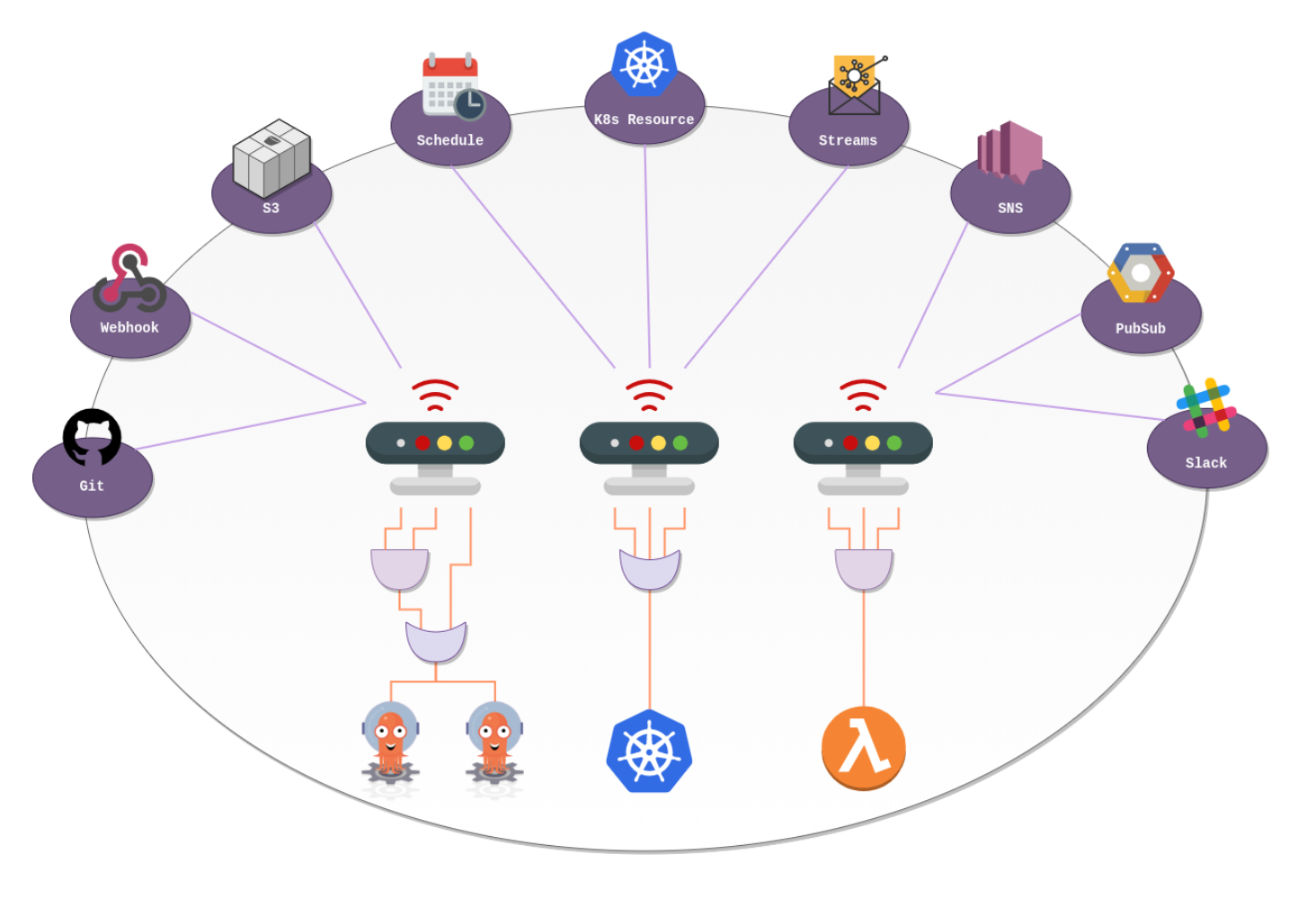
예를들어 AWS SQS의 큐에 메시지가 입력되면, Argo Events가 해당 큐를 모니터링하다가 메시지를 감지하고, 해당 메시지의 내용을 인자로 사용하여 연결된 Argo Workflow를 트리거 할 수 있습니다. 이 외에도 매우 다양한 이벤트 소스와 트리거를 지원하고 있기때문에 공식 문서에서 목록을 확인 해 보고 원하는 대로 구성을하기만 하면 됩니다.
Argo Workflow와 Argo Events의 설치/운영 방법에 대한 내용은 공식 문서를 참고해주시면 되고, 이 글에서는 앞서 설명했떤 fare_crawler와 fare_updater에 어떻게 적용되었는지를 중점적으로 살펴보겠습니다.
실제 yaml 예제
이벤트 소스 (Event Source)
fare_crawler를 정해진 시간에 수행하기 위해서 단순히 Cron Workflow를 사용해도 되지만, AWS CLI가 기본적으로 설치된 상태인 Jenkins 서버에서도 편리하게 트리거 할 수 있도록 AWS SQS를 이벤트 소스로 사용했습니다.
AWS CLI만 있으면 아래처럼 명령어를 수행해서 언제든지 이벤트를 트리거 할 수 있습니다.
aws sqs send-message \
--queue-url https://sqs.ap-northeast-1.amazonaws.com/xxxxxxx/dev-fare-crawler \
--message-body '{ "outputFolder": "2024-01-20"}'
실제 이벤트 소스의 정의는 다음과 같습니다.
apiVersion: argoproj.io/v1alpha1
kind: EventSource
metadata:
name: fare-crawler-aws-sqs
namespace: argo-events
spec:
sqs:
sqs-message-received:
jsonBody: true
# 여기서 접근하는 시크릿의 경우 argo-events가 설치된 argo-events namespace에 존재해야 읽어올 수 있음
accessKey:
name: aws-secret
key: accesskey
secretKey:
name: aws-secret
key: secretkey
region: ap-northeast-1
queue: dev-fare-crawler
waitTimeSeconds: 20
센서 (Sensor)
센서는 아래 yaml 코드 중 eventSourceName: fare-crawler-aws-sqs 설정에 의해 이벤트 소스와 연결됩니다.
이렇게 연결된 이벤트 소스에서 이벤트가 감지되었을때 triggers: 섹션에 인라인으로 정의된 Workflow가 실행되도록 설정되어 있습니다.
각 부분에 대한 더 자세한 설명은 코드 내에 주석을 통해 설명하도록 하겠습니다.
apiVersion: argoproj.io/v1alpha1
kind: Sensor
metadata:
name: fare-crawler-aws-sqs
namespace: argo-events
spec:
template:
serviceAccountName: operate-workflow-sa
dependencies:
- name: fare-crawler-dep
eventSourceName: fare-crawler-aws-sqs
eventName: sqs-message-received
triggers:
- template:
name: trigger-fare-crawler
k8s:
group: argoproj.io
version: v1alpha1
resource: workflows
operation: create
parameters:
# SQS를 통해 전될된 메시지(Input.body) 내용 중 outputFolder라는 필드 값을 읽어와서 다양한 작업을 수행합니다.
# (해당 필드값이 존재하지 않을 경우 빈 스트링을 기본값으로 사용합니다)
- src:
dependencyName: fare-crawler-dep
dataTemplate: ''
# outputFolder 값을 아래쪽에 인라인 정의된 Workflow의 첫번째 인자로 넣어줍니다.
dest: spec.arguments.parameters.0.value
- src:
dependencyName: fare-crawler-dep
dataTemplate: '-'
# outputFolder 값을 아래쪽에 인라인 정의된 Workflow의 metadata.generateName 필드 값에 append 합니다.
dest: metadata.generateName
operation: append
source:
resource:
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
# 쿠버네티스에 생성되는 Pod의 이름을 결정합니다.
# 결과적으로 fare-crawler-- 형태로 생성됩니다.
generateName: fare-crawler-
# Workflow가 수행될 namespace를 명시합니다. 이부분은 자신이 사용할 쿠버네티스 클러스터의 상황에 맞게 적절히 설정해주세요.
namespace: dev
spec:
imagePullSecrets:
- name: squarelabkuber-cred
# Argo Workflow 설치과정에서 생성한 서비스 어카운트를 넣어주시면 됩니다.
serviceAccountName: workflow
entrypoint: main
arguments:
parameters:
- name: outputFolder
- name: fareUpdaterQueueName
value: dev-fare-updater
activeDeadlineSeconds: 72000 # 20h
ttlStrategy:
# 수행되는 Workflow들의 TTL이 제대로 설정되지 않는 경우 해당 Workflow의 기록이 계속해서 쿠버네티스상에 그대로 남게됩니다.
# 이 경우 쿠버네티스 Control Plane이 느려지거나 메모리 부족 현상이 생길 수 있으니 적절한 TTL 설정이 필수입니다.
secondsAfterSuccess: 3600 # 성공한 Workflow를 3600초간 유지
secondsAfterFailure: 86400 # 실패한 Workflow를 86400초간 유지
templates:
# Workflow 정의
- name: main
steps:
# 2개로 샤딩하여 병렬로 항공권 운임 데이터를 수집합니다.
- - name: fare-crawler-1
# 아래쪽에 정의된 템플릿 기반으로 작업 단계를 구성합니다.
template: launch-fare-crawler
arguments:
parameters:
# 여기 정의된 값을 아래쪽 컨테이너이너 설정에서 형태로 읽어서 사용합니다
- name: message
value: '{"shardingOptions":{"shards":2,"shardIndex":1,"outputFolder":""}}'
- name: fare-crawler-2
template: launch-fare-crawler
arguments:
parameters:
- name: message
value: '{"shardingOptions":{"shards":2,"shardIndex":2,"outputFolder":""}}'
# 위의 fare_crawler 수행이 모두 성공적으로 종료되면 SQS에 메시지를 보내서 fare_updater를 트리거 합니다.
- - name: trigger-fare-updater
template: launch-aws-cli
arguments:
parameters:
- name: queueName
value: ''
- name: message
value: '{"targetFolder":""}'
# Workflow 정의에서 참조해서 사용하는 템플릿
- name: launch-fare-crawler
metadata:
labels:
app: fare-crawler
inputs:
parameters:
- name: message
nodeSelector:
instanceType: general
container:
image: kyte/fare_crawler:${DOCKER_TAG}
imagePullPolicy: Always
args: ['']
- name: launch-aws-cli
inputs:
parameters:
- name: queueName
- name: message
nodeSelector:
instanceType: general
container:
image: amazon/aws-cli:2.7.25
args:
- 'sqs'
- 'send-message'
- '--queue-url'
- 'https://sqs.ap-northeast-1.amazonaws.com/xxxxxxxxxxxxxx/'
- '--message-body'
- ''
env:
- name: AWS_ACCESS_KEY_ID
value: xxxxxxx
- name: AWS_SECRET_ACCESS_KEY
value: xxxxxxx
# Workflow의 Pod들이 동일한 쿠버네티스 노드에 몰려서 수행되지 않도록 설정합니다.
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- fare-crawler
topologyKey: kubernetes.io/hostname
여기서는 fare_crawler 에 대해서만 설명했는데, fare_updater는 거의 동일한 방식으로 구성되어있기 때문에 더이상의 자세한 설명은 생략하겠습니다.
Workflow 수행 결과 확인
위 설정을 통해 수행된 결과는 Argo Workflow 대시보드를 통해 편하게 확인을 할 수 있습니다. 대시보드를 통해서 Workflow의 상세 내용을 보면 DAG(Directed Acyclic Graph) 형태로 샤딩된 작업이 병렬 수행된 후 다음 작업이 수행된 것을 볼 수 있습니다.
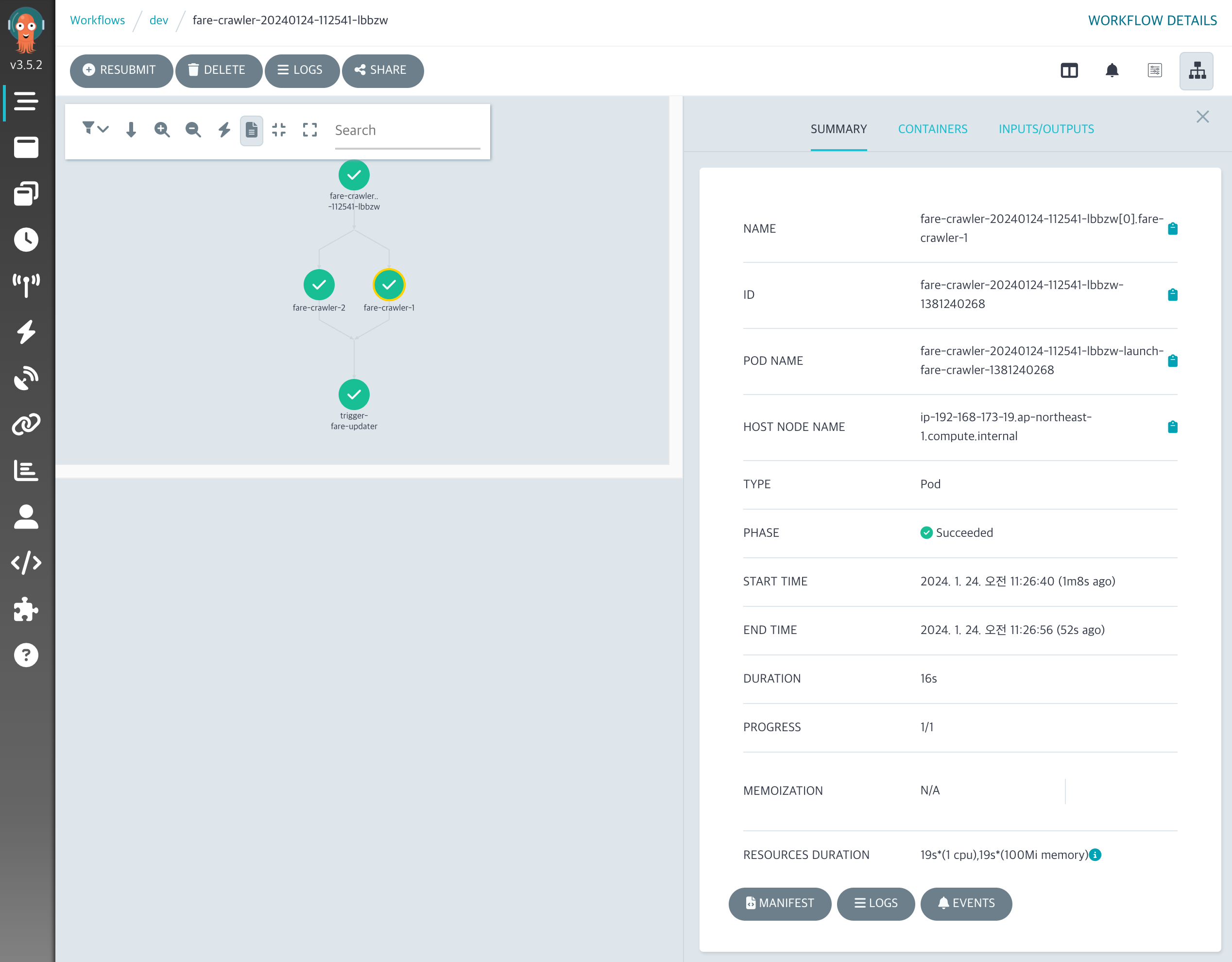
위 화면을 통해서 각 컨테이너가 실행되면서 발생한 로그도 바로 조회하여 볼 수 있기 때문에 매우 편리합니다.
마무리
이번 프로젝트를 통해 최저가 항공 요금을 수집하고 제공하는 복잡한 데이터 파이프라인을 성공적으로 구축했습니다. 이 과정에서 Argo Workflow와 Argo Events의 유연성과 강력한 기능을 통해 매우 효율적이고 확장 가능한 시스템을 단시간에 개발 할 수 있었습니다. 차후에 항공 요금을 수집해야하는 목적지 등이 늘어나더라도, 샤드 갯수만 조정해주면 원하는 시간 내에 데이터 수집을 완료할 수 있는 유연한 시스템이라 더 만족스러웠습니다. 이러한 성과는 단순히 기술적인 측면을 넘어서, 사용자에게 더 나은 서비스를 제공하는 데 크게 기여했습니다. 사용자들은 이제 더 많은 목적지, 더 많은 날짜의 항공 요금을 빠르고 효율적으로 비교할 수 있게 되었으며, 이는 항공권 구매 결정 과정을 간소화시켜서 매출 증대로 이어질 수 있을것이라 기대합니다.
이 글이 항공 요금 데이터 파이프라인에 대한 통찰을 제공하고, Argo Workflow와 Argo Events의 강력한 기능을 이해하는 데 도움이 되었기를 바랍니다. 여러분의 프로젝트에도 이러한 도구들이 어떻게 유용하게 적용될 수 있는지 고려해보시길 권장합니다.