 이성빈|Oct 7, 2024
이성빈|Oct 7, 2024
Jenkins는 소프트웨어 개발의 빌드, 테스트, 배포를 자동화하는 오픈 소스 CI/CD 도구입니다. 다양한 플러그인을 통해 유연하게 파이프라인을 구성하여 효율적인 작업 처리가 가능합니다.
기존에는 Jenkins pipeline 작업만을 위한 2~3개의 kubernetes node를 생성하고, 각 node 마다 jenkins agent pod을 DaemonSet 형태로 띄우는 형태로 모든 jenkins pipeline들이 수행되고 있었습니다. 이로 인해 생겼던 여러가지 문제를 kubernetes plugin 도입과 spot instance 사용을 통해 빌드 프로세스를 개선하고, AWS 비용을 상당량 줄이게 된 과정을 소개합니다.
문제 상황
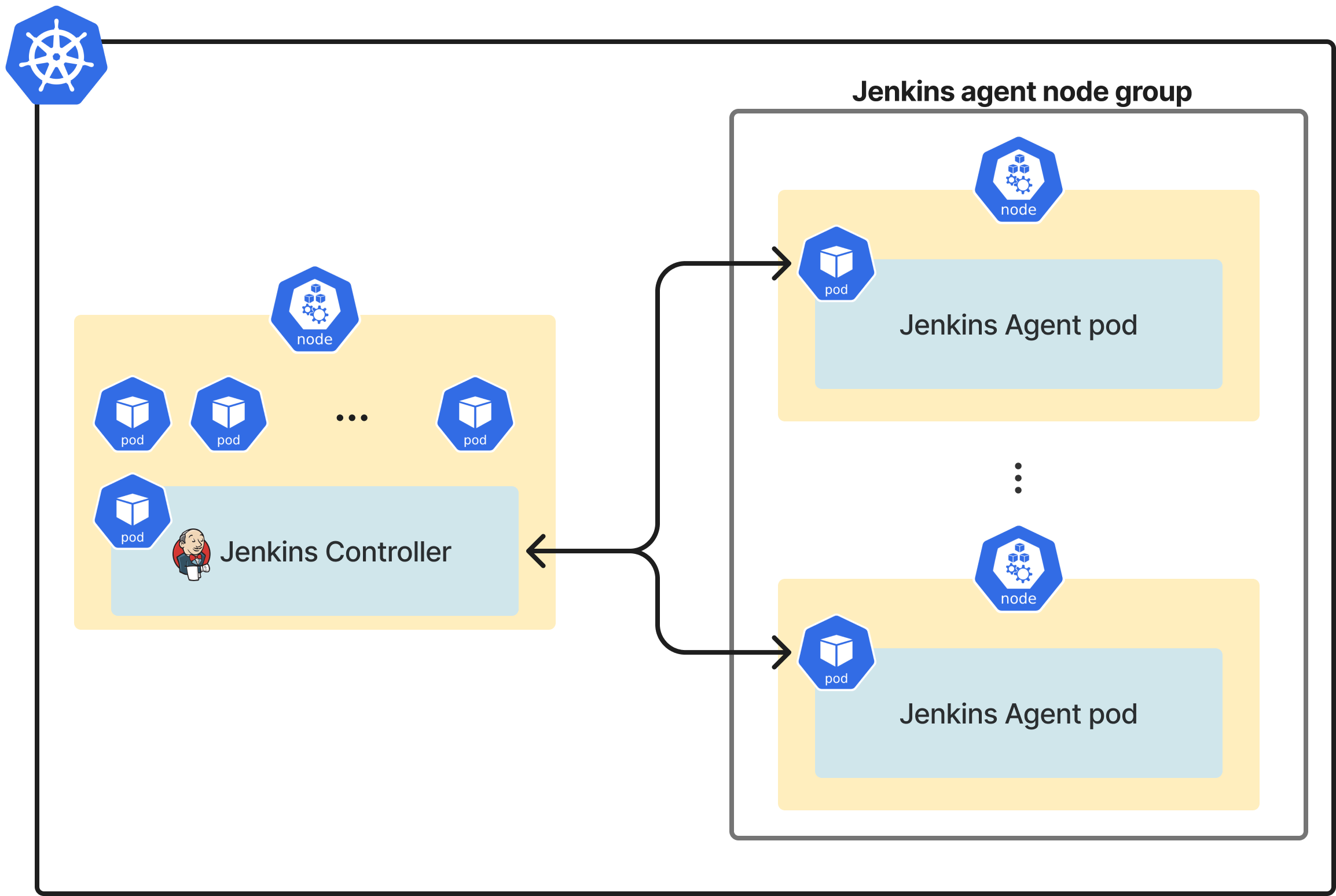
기존에 Jenkins를 사용하던 구조는 위와 같습니다. Jenkins Controller(master)와 Jenkins agent pod들을 각각 연결시켜 놓은 구조입니다. 이 때 Jenkins agent pod은 node 1개를 차지하는 형태로, 각 node 마다 gradle 빌드 캐시와 git history가 관리되고 있었습니다. 즉, 고정 node를 Jenkins agent로 사용하고 있었던 것인데, 이렇게 고정 node를 사용할 때의 문제를 한 마디로 요약하면 자원을 효율적으로 사용하기 어렵다는 것입니다. 구체적으로는 다음과 같이 네가지 정도로 구분할 수 있겠습니다.
1. Agent 수
대부분의 빌드, 배포, 테스트의 과정은 주간 시간에 일어나기 마련이어서, 퇴근 시간 이후에는 유휴 자원으로 인해 비용이 소모되곤 합니다. 그렇기 때문에 퇴근 시간 이후의 유휴 자원을 줄일 수 있다면, 즉, Jenkins agent 개수를 줄일 수 있다면, 낭비되는 비용을 절약할 수 있을 것 입니다. 다만, DB 백업, 각종 데이터 크롤링, dev 서버 빌드 & 배포 등 다양한 작업들은 우리가 잠을 자고 있는 밤에도 수행되고 있기 때문에, 적절한 양의 agent를 유지해 놓을 수 있어야합니다. 아래와 같은 상황이 일어나면 job이 수행되지 않을 수 있기 때문입니다.
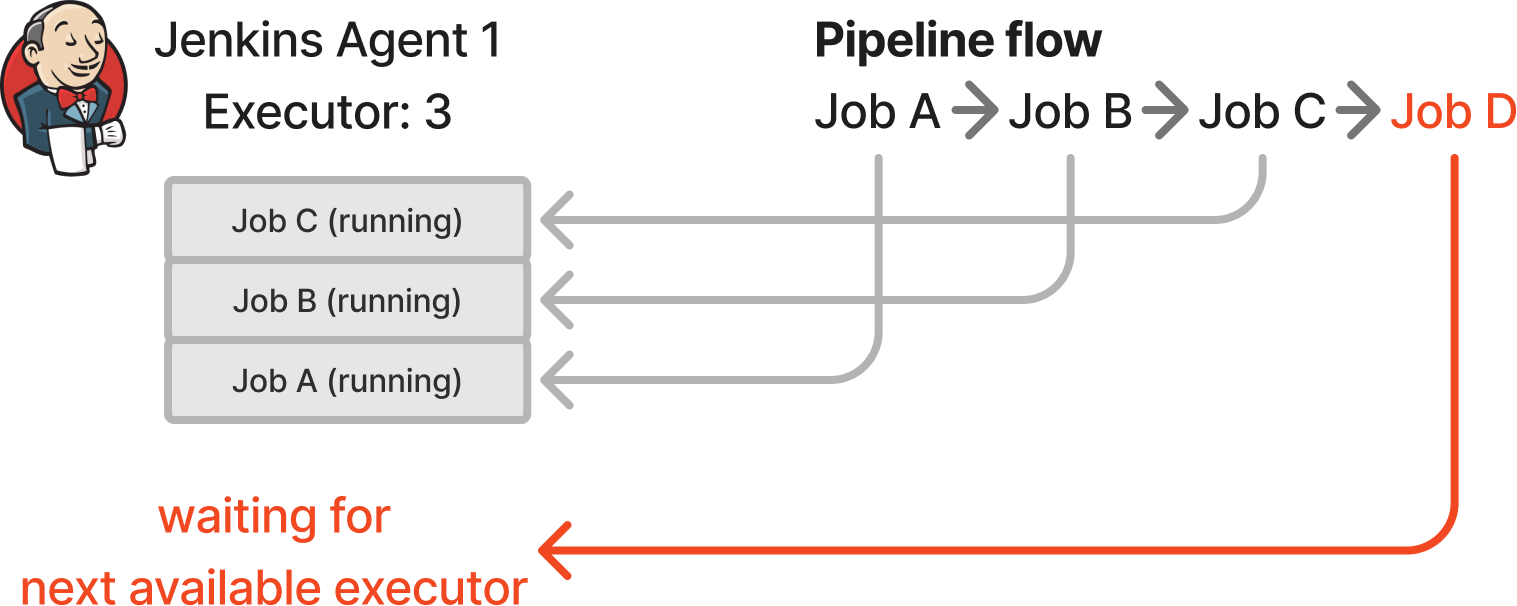
Jenkins에서는 agent 마다 executor 수를 정해놓게 되는데, 이는 한개의 agent가 최대 처리할 수 있는 pipeline 수에 해당합니다. jenkins pipeline을 사용할 때, 다른 job을 참조하여 호출하는 식으로, 여러개의 job을 연결해서 사용하는 것은 일반적입니다. 만약 위와 같이 executor 숫자보다 연쇄적으로 실행되어야하는 job의 개수가 더 많다면, Job D는 자신이 실행될 수 있는 executor를 기다리기만 하고 있을 것이고, Job A~Job C는 complete 되지 않고 executor 자리를 차지하고 있을 것입니다. 중요한 pipeline이 먼저 실행되도록 우선 순위 관리를 할 수는 있지만, 이런 구조에서 문제 상황을 방지하는 방법은 agent 수(인스턴스 수)를 늘리는 것 말고는 쉽게 떠오르지 않습니다.
2. 리소스 관리
각 pipeline이 요구하는 리소스 사양을 적절히 만족시키기 어렵습니다.
예를들어 메모리가 16GB인 jenkins agent의 executor 수를 3개로 설정해놓고, 2개의 프로젝트 A, B를 동시에 빌드하는 상황을 가정해봅시다. 만약, A를 빌드하는 과정에서 필요한 메모리는 10GB 이상이고, B를 빌드하는 과정에서 필요한 메모리가 8GB 이상이라면, A와 B는 동일한 agent에서 실행될 수는 있지만, 빌드 과정에서 OOM으로인해 실패하게 될 것입니다. A와 B가 성공적으로 빌드되는 것을 보장하려면, agent 마다 executor 수를 1개로 설정하거나, throttle concurrent builds plugin을 사용해서 동일한 category를 설정하고 Maximum Concurrent Builds Per Node 값을 1과 같이 설정할 수 는 있겠습니다. 그러나, 이 역시 컴퓨팅 리소스를 낭비하는 것입니다. 만약 메모리를 100MB만 사용하는 job C, D, E가 있을 경우, 이 job들을 모두 실행할만한 리소스가 있음에도 불구하고 하나의 노드당 1개의 job이 실행되기 때문입니다.
3. job 실행이 단시간에 몰리는 경우
job 실행이 단시간에 급격하게 많아지게 된다면, 기존 방식으로는 대응이 어렵습니다. 미리 띄워둔 jenkins agent 수와, 각 agent의 executor 수는 고정되어 있기 때문입니다.
예를 들어, 3개의 jenkins agent가 있고 각 agent마다 3개의 executor가 설정되어 있는 경우, 총 9개의 job을 동시에 처리할 수 있습니다. 하지만, 100개의 job이 한 번에 실행된다면, 91개의 job은 실행 대기 상태로 기다려야 합니다.
4. DIND(Docker-in-Docker) 구조
Jenkins agent에서 도커 이미지 빌드 시 DIND 구조를 사용하고 있었기 때문에, privileged 옵션을 사용해야 했습니다. 이로 인해 보안 취약점이 발생할 수 있는 위험이 있었습니다. 또한, Docker가 Docker 내부에서 실행되는 과정에서 중첩된 파일 시스템 계층이 생겨 빌드 과정에서 성능 저하가 발생할 수 있었습니다.
문제 해결하기
kubernetes plugin을 사용하면 하나의 job마다 pod을 생성할 수 있습니다. 이 때 필요한 만큼의 resource(cpu / memory)를 할당해주며, resource가 부족할 때 cluster autoscaler가 작동되면서 노드가 새롭게 생성되도록 한다면, executor 수에 제한을 받지 않고, 실제로 필요한 resource 만큼 사용할 수 있습니다. kubernetes는 자원의 할당과 확장이 유연하기 때문에, job이 급격하게 몰릴 경우에도 필요한 만큼의 pod를 빠르게 생성할 수 있습니다. 또한 node에 scheduling 되는 각 job에 대한 pod을 병렬로 처리되며, job이 끝난 후 pod는 자동으로 삭제되기 때문에 자원 낭비도 최소화할 수 있습니다. 클러스터의 자원 한도 내에서는 거의 무한정으로 확장 가능하므로, 일시적인 job 폭증에도 빠르게 대응할 수 있습니다.
도커 이미지 빌드 과정에서 DIND 구조를 제거하기 위해서는 OCI(Open Container Initiaive) 규격을 따르는 여러가지 build tool들(kaniko, buildkit, buildah)을 비교해보게 되었습니다. 결론적으로는, 참고할 레퍼런스가 많고, 보안적 고려사항이 적은 kaniko를 사용하는 것으로 방향을 정할 수 있었습니다.
Kubernetes plugin을 더 잘 사용하기 위한 daily build
kubernetes plugin을 적용하기 위해서는 Jenkins와 kubernetes cluster를 연결해줘야합니다. kubernets plugin의 Configuration 문서 를 참고해서 jenkins와 eks cluster를 연결해주었다면, 다음과 같이 agent에 kuberentes pod 스펙을 작성해서 전달할 수 있습니다.
pipeline {
agent {
kubernetes {
yaml """
apiVersion: v1
kind: Pod
spec:
containers:
- image: image:tag
name: image_name
resources:
requests:
cpu: "0.5"
memory: "4Gi"
limits:
cpu: "1"
memory: "8Gi"
"""
}
}
// ...
}
이렇게 생성된 pod은 정의한 pipeline이 종료되면 pod도 같이 종료되므로, node의 자원을 더욱 효율적으로 사용할 수 있습니다. (종료된 후에 pod 정보를 확인하고 싶다면, podRetention 옵션 등을 설정해야합니다.)
기존 agent에서 잘 작동하던 pipeline을 kubernetes pod에서 작동할 수 있도록 수정하기만 하면 될 것 같지만, 가장 큰 문제는 빌드 캐시가 pod 이 종료되면서 사라지기 때문에, 매번 아무런 캐시가 없는 상태로 빌드가 실행되어야한다는 문제가 있습니다.
저희는 gradle로 모노레포 프로젝트를 관리하고 있고, 서버의 각 프로젝트는 Kotlin 혹은 Node.js로 개발하고 있습니다. 서버 빌드 과정에서 외부 dependency가 항상 필요한데, pod이 생성될 때마다 dependency를 매번 설치하게 된다면 많은 리소스를 낭비하게 될 것 입니다. 빌드 캐시를 유지하고 최신화 하기 위한 방법으로는 매일 repository를 clone 하고, 모든 dependency들을 미리 설치 해놓은 container를 pod에서 사용할 수 있도록 daily build 이미지를 만들게 되었습니다. 또한 gradle build cache node 서버를 별도로 구성하여, CI 환경에서는 remote build cache를 사용할 수 있도록 할 수 있었습니다.
Kaniko로 dailybuild 이미지 만들기
도커 이미지 빌드 과정에서 DIND 구조를 제거하기 위해서는 Kaniko를 사용했습니다. Kaniko는 도커 데몬없이, kubernetes pod 내에서 실행되는 구조여서 privileged 옵션 없이 컨테이너 이미지를 빌드할 수 있습니다. 또한 layer 단위로 캐싱을 할 수 있어서 빌드 속도를 높일 수 있습니다.
아래는 daily build의 Dockerfile의 일부 입니다.
FROM (jdk, node 등 필요한 패키지들을 미리 설치해놓은 이미지)
ARG BUILD_CACHE_PASSWORD
ENV BUILD_CACHE_PASSWORD=${BUILD_CACHE_PASSWORD}
ENV CI=true
RUN mkdir -p /squarelab
COPY . /squarelab/
WORKDIR /squarelab/client
RUN yarn install
WORKDIR /squarelab/server
RUN ./gradlew buildAllWithoutArtifact
Dockerfile의 위치는 repository의 최상단입니다. repository의 모든 내용을 COPY 하고 필요한 내용들을 미리 install하는 과정 입니다.
buildAllWithoutArtifact 는 custom gradle task 입니다. jvm 서버의 경우 build 까지 수행하게 되면 jar package를 생성하게 됩니다.(Task graph 참고) 이는 이미지 사이즈가 커지는데 기여합니다. 그러나 classes 까지만 수행하면 불필요한 artifact들은 포함되지 않아서 빌드 사이즈를 줄일 수 있습니다. node 서버의 경우에는 build 까지 수행하면 node_modules에 package들이 install 될 것입니다. 이는 다음과 같이 구현할 수 있습니다.
tasks.register('buildAllWithoutArtifact')
// Configure tasks after all projects have been evaluated
gradle.projectsEvaluated {
rootProject.subprojects.each { project ->
if (project.tasks.findByName('assemble') != null) {
String taskName = "triggerClassesFor${project.path.replace(':', '_')}"
Task triggerClassesTask = project.tasks.create(taskName) {
// Do not use 'build' task for jvm projects, which generate jar packages for distribution.
// This reduces the size of 'dailybuild' docker image.
dependsOn project.tasks.classes
}
buildAllWithoutArtifact.dependsOn(triggerClassesTask)
} else if (project.tasks.findByName('build') != null) {
String taskName = "triggerBuildFor${project.path.replace(':', '_')}"
Task triggerBuildTask = project.tasks.create(taskName) {
dependsOn project.tasks.build
}
buildAllWithoutArtifact.dependsOn(triggerBuildTask)
}
}
}
daily build 이미지를 생성할 때, kaniko는 jenkins pipeline에서 아래와 같이 사용할 수 있습니다.
pipeline {
agent {
kubernetes {
yaml """
apiVersion: v1
kind: Pod
spec:
containers:
- name: kaniko
image: gcr.io/kaniko-project/executor:v1.23.2-debug
tty: true
command:
- /busybox/sleep
- infinity
resources:
requests:
memory: "13.5Gi"
limits:
memory: "13.5Gi"
"""
defaultContainer "kaniko"
}
}
environment {
BUILD_CACHE_PASSWORD = credentials('BUILD_CACHE_PASSWORD')
}
stages {
stage('VCS Checkout') {
steps {
checkout()
}
}
stage('Build Image') {
environment {
PATH = "/busybox:/kaniko:$PATH"
}
steps {
container(name: "kaniko", shell: "/busybox/sh") {
script {
def dockerfileDir = '.'
sh """#1/busybox/sh
/kaniko/executor \
--compressed-caching=false \
--context ${dockerfileDir} \
--destination (dailybuild repository):(tag) \
--build-arg=BUILD_CACHE_PASSWORD=${env.BUILD_CACHE_PASSWORD}
"""
}
}
}
}
}
}
Jenkinsfile에서 유의해야되는 점은, debug kaniko 이미지를 이용했다는 것입니다. jenkins에서 checkout 해온 내용을 가지고 dockerfile을 빌드하는 과정에서 shell을 사용할 수 있어야하는데, 기본 kaniko executor 이미지에는 shell이 없습니다. 그래서 debug 이미지에 있는 busybox를 사용해서 context와 destination 등의 옵션을 전달했습니다.
또한 --compressed-caching=false 옵션을 준 것을 볼 수 있는데, 이 옵션을 꺼줘야 메모리 부족으로 인해 빌드가 실패하는 것을 막을 수 있었습니다. (관련 이슈)
Spot instance와 함께 daily build 이미지 사용하기
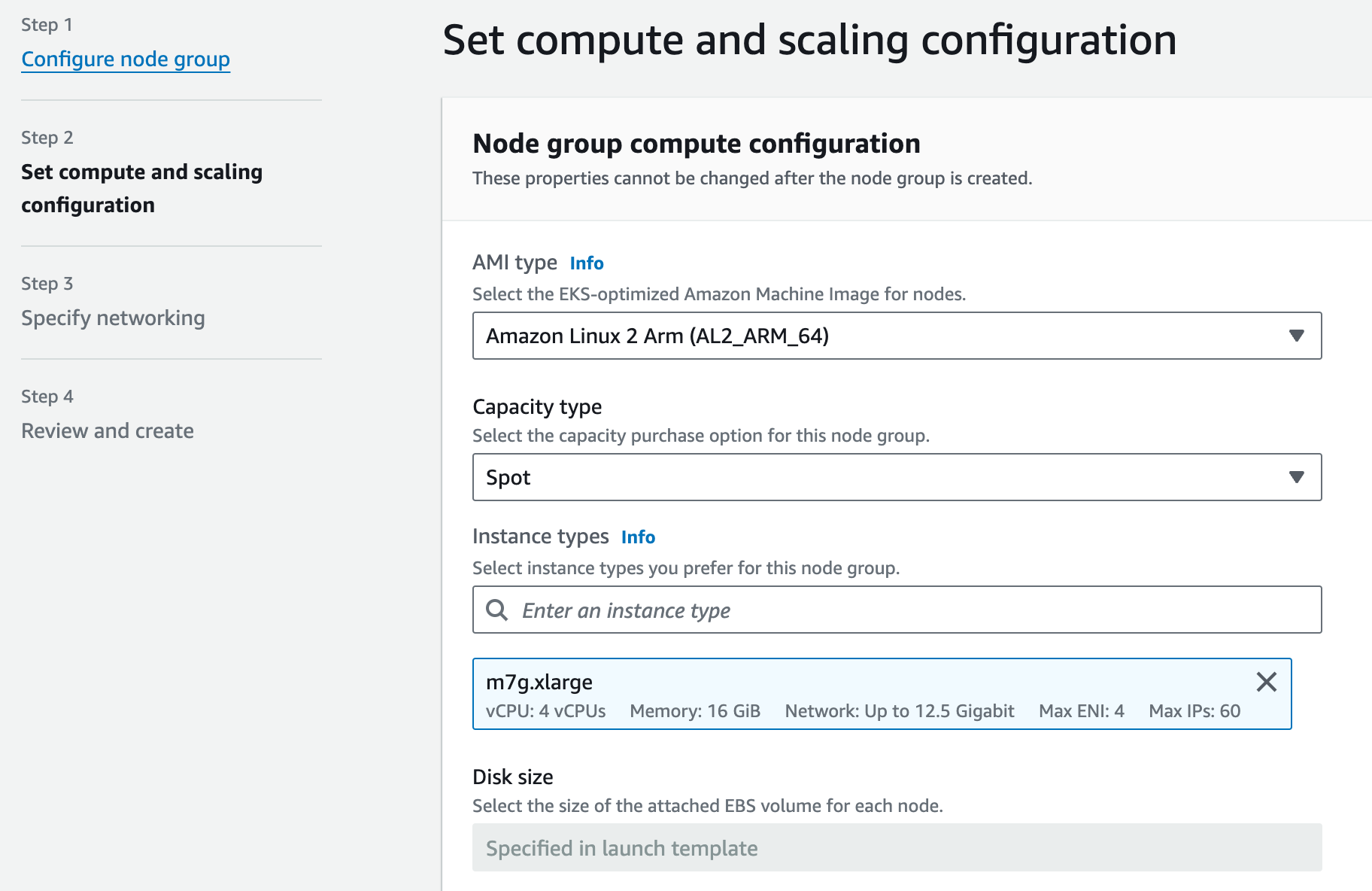
eks에서 노드 그룹을 생성할 때, 위와 같이 해당 노드 그룹이 spot instance를 사용하도록 할 수 있습니다. 이 때, 노드 그룹에 taint를 적절하게 설정하고, jenkinsfile의 pod yaml spec에 tolerations를 잘 설정해준다면, jenkins pipeline에 해당하는 pod들만 spot instance를 사용할 수 있습니다. 노드 그룹의 maximum size도 적절한 값으로 설정해서, 작업이 몰렸을 때 너무 많은 instance가 뜨지 않도록 방지할 수 있습니다.
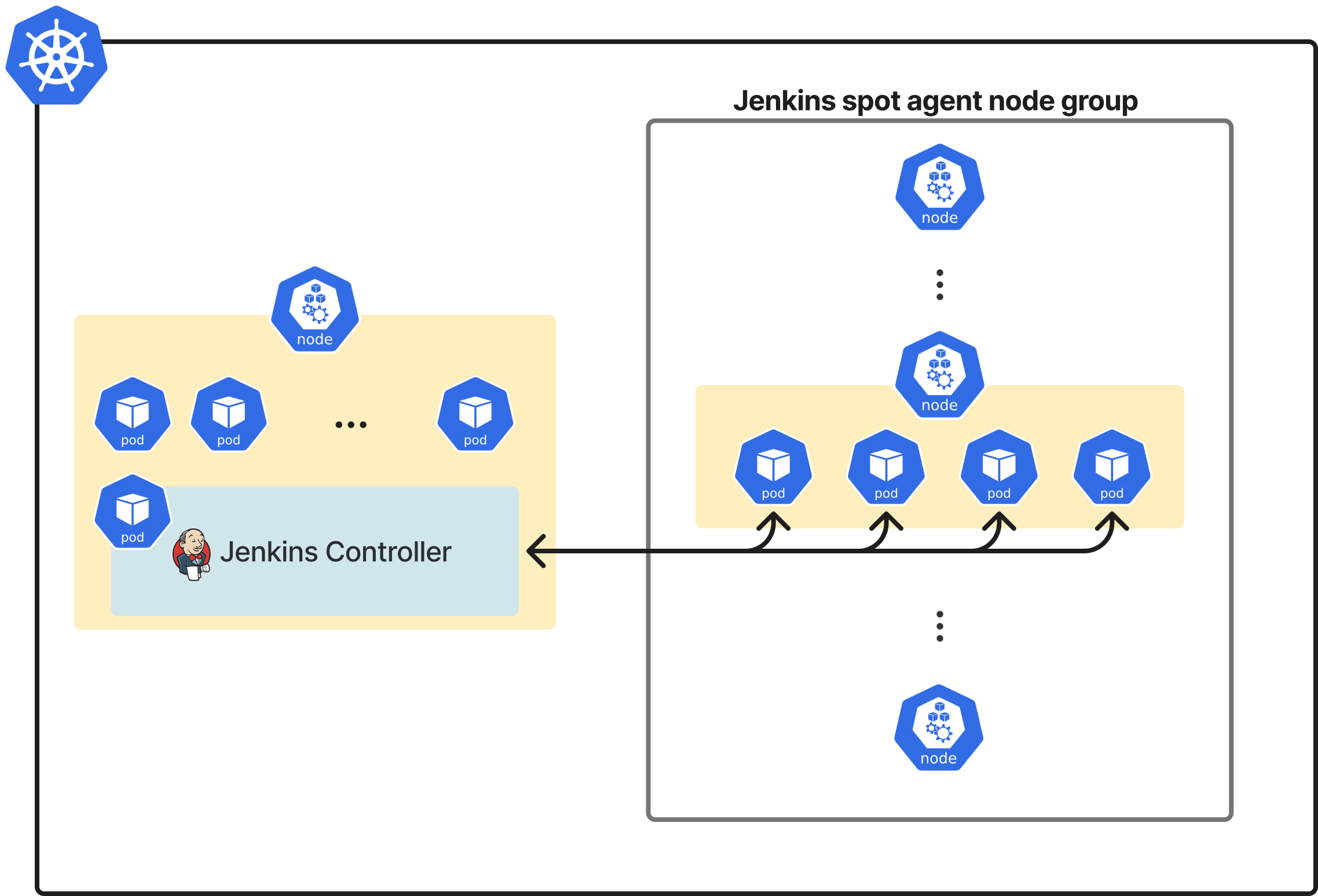
이제 위와 같은 형태로, agent의 executor의 수에 관계 없이, pod yaml spec에서 정의한 resource만 만족시킬 수 있다면 안정적으로 pipeline을 실행시킬 수 있는 환경이 되었습니다. 만약 현재 떠있는 node에 pod을 schedule 할 수 없다면, cluster autoscaler에 의해서 node가 추가로 생성될 것이고, node에 schedule 된 pod이 없다면 해당 node는 terminate 되는 과정을 거치게 될 것입니다. agent 마다 executor 숫자를 직접 지정하는 것보다 훨씬 효율적으로 컴퓨팅 자원 활용이 가능합니다.
다만, 아래와 같은 내용에 대한 고려가 필요합니다.
1. node 생성시 최초 Image pull 과정 필요
Jenkinsfile에서 dailybuild 이미지를 사용하도록 pod을 정의했고, autoscaling으로 새롭게 생성된 node 라면 dailybuild image를 pull 하는 과정이 한번 필요합니다. 이후 해당 node가 terminate 되기 전에 dailybuild 이미지를 사용하는 jenkins pipeline이 실행된다면, 한번 불러온 docker image는 노드에 캐시되어 있기 때문에, 이 때는 image를 pull 할 필요 없이 바로 script가 실행됩니다. 저희의 경우, daily build 이미지의 크기 때문에, 최초 pull 시에는 2~3분정도의 시간이 필요했습니다. 그러나, 주간에는 엔지니어들이 작성한 코드들의 리뷰 과정에서 테스트가 지속적으로 실행되게 되므로, image pull로 인한 delay를 느끼기는 어려웠습니다.
2. jnlp 컨테이너의 경로 문제
kubernetes plugin을 사용해서 pod을 생성하게 되면, 정의한 container 외에 jnlp 컨테이너가 추가로 뜨게 됩니다. jnlp 컨테이너는 default로 /home/jenkins/agent/workspace/{pipeline_name} 이하 경로로만 접근할 수 있습니다. 따라서 상위 경로로 이동하게 되는 경우에는 권한 오류가 발생합니다. 위와 같이 dailybuild 이미지를 생성한 경우에는 /squarelab 폴더에 모든 내용을 담아놨기 때문에, Jenkinsfile에서 dir(“/squarelab”) 과 같이 접근할 수 없습니다. 그러나 명시적으로 선언한 dailybuild container block 안에서는 sh “cd /squarelab” 과 같이 접근할 수 있습니다.
기존의 pipeline이 dir(“folder”) block을 사용한다면, 아래와 같이 dailybuild 컨테이너에서 jnlp가 사용하고 있는 경로에 worktree를 생성하도록 하는 것도 방법이 될 수 있습니다.
steps {
container("dailybuild") {
script {
workingDirectory = sh(script: "pwd", returnStdout: true).trim()
sh "cd /squarelab && git worktree add -b kaniko/${params.branch} \"${workingDirectory}\" HEAD"
sh "git config --global --add safe.directory \"${workingDirectory}\""
...
3. 하나의 kaniko, 하나의 빌드
하나의 pipeline안에서 여러개의 서버를 빌드하는 구조라면, 서버 하나만 빌드하는 pipeline에서 kaniko로 해당 서버를 빌드할 수 있도록 하고 해당 pipeline을 여러번 호출하는 구조로 변경하는게 좋을 것 같습니다. kaniko container에 cleanup 옵션을 사용하면서 여러개의 서버를 빌드하고 푸시할 때, 빌드 에러가 발생하기도 했습니다.
4. 적절한 resources 설정
kubernetes cluster가 pod scheduling을 최적화하고, pipeline 실행의 안정성을 보장하기 위해, pipeline을 실행해보면서 해당 파이프라인이 어느정도의 리소스를 사용하는지를 측정하고, resources spec을 적절한 값으로 반영하는게 좋습니다.
성과
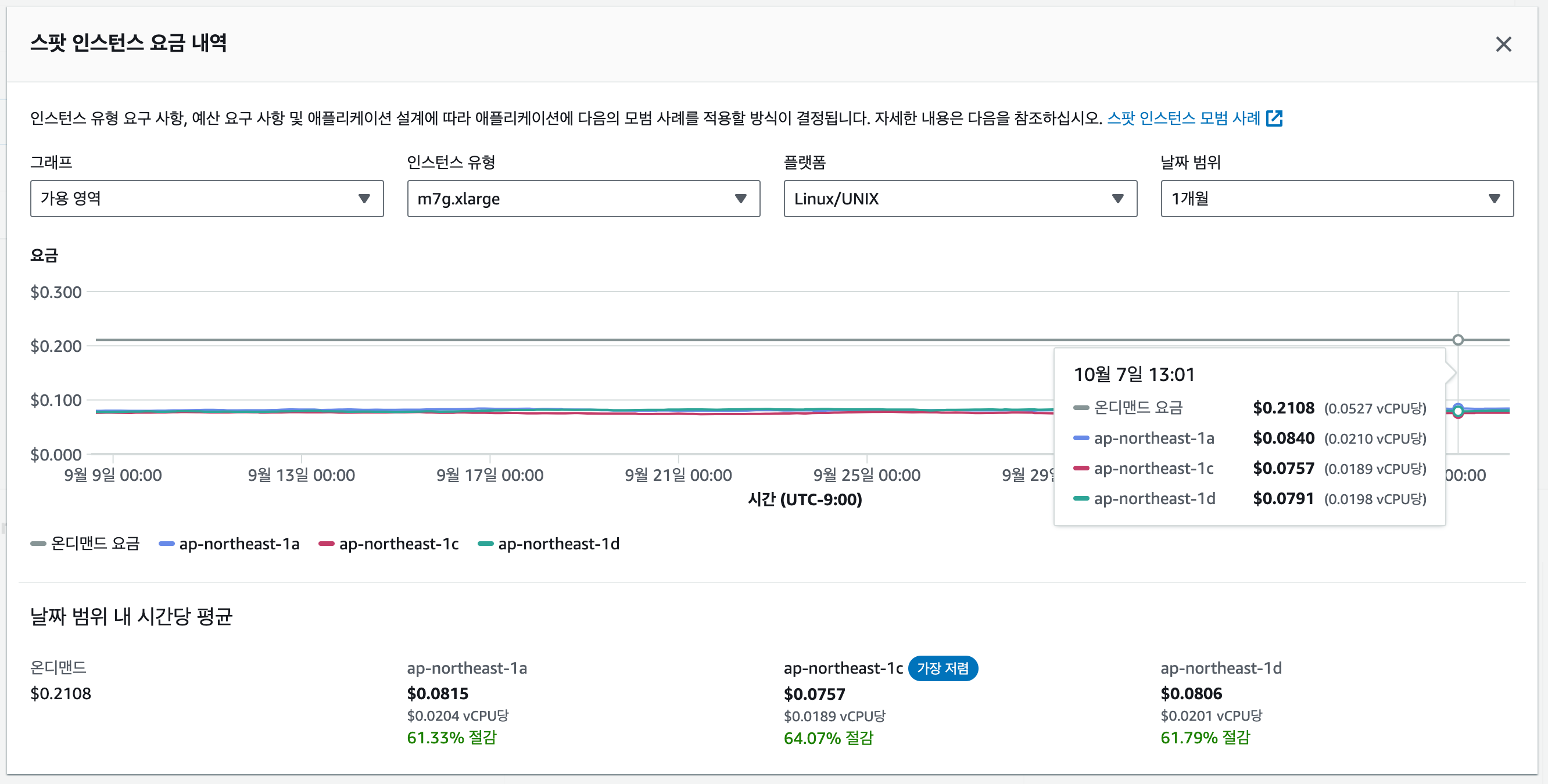
위 사진은 저희가 주로 사용하는 m7g.xlarge 인스턴스(4 vCPUs, 16GB)의 spot instance 가격 그래프 입니다.
On-Demand price는 시간 당 $0.211이고, 1년 Reserved Instance 가격은 시간 당 $0.140 입니다.
개선 전, 1년 Reserved Instance 2대 기준, 한달 고정 비용은 24시간 x 30일 x 2대 x $0.140 = $201.6 이었지만,
개선 후, 한달 간 실제 사용한 spot instance 사용 비용은 220.3시간 x $0.084 + 213.23 시간 x $0.076 + 149.41 시간 x $0.080 = $46 정도 였습니다.
spot instance를 사용한 시간은 총 589시간(고정 인스턴스 대비 사용시간 41% 절감)이었고, 총 비용은 $46(예약 인스턴스 대비 비용 77% 절감) 으로 상당량 절약할 수 있었습니다. 😮
결론
Spot instance를 사용할 때는 작업 중단 가능성을 감안해야합니다. 코드를 테스트하고, 빌드, 배포하는 환경에서는 작업이 중단 되더라도 재시도하면 되기 때문에 spot instance를 사용하는 것이 적절해보입니다. 비용적인 측면에서도, on-demand instance 보다 spot instance를 사용하는게 컴퓨팅 자원을 훨씬 효율적으로 사용할 수 있음을 확인할 수 있었습니다. 노드가 새롭게 생성될 때 Daily build 이미지를 한번 pull 하게 되지만, 이 때 걸리는 delay는 크게 느껴지지 않았습니다. 결론적으로 서버 비용을 상당히 줄이면서, 배포 프로세스를 최적화할 수 있었습니다.
Spot instance를 사용할 때 고려하게 됐던 여러가지 내용들을 이 글에 작성해보았는데, 다른 분들께도 AWS 비용을 최적화 하는데 도움이 되었으면 좋겠습니다.