 권영재|Aug 4, 2023
권영재|Aug 4, 2023
이번 글에서는 카이트 항공 서비스 리뉴얼을 하는 과정에서 만났던 ‘자동 재시도 요청으로 인한 중복 예약 생성 오류’에 대한 트러블 슈팅 과정을 단계적으로 소개해드리려고 합니다. 이 글이 문제가 발생했을 때 실무에서 어떤식으로 원인을 찾고 문제를 해결해 나가는지 궁금해하시는 분들에게 도움이 되었으면 좋겠습니다.
중복 예약 생성 문제
이번에 카이트 항공 서비스에 대한 대대적인 리뉴얼을 하면서 항공 예약시 사용하는 기존 레거시 API를 모두 버리고, 완전히 새로운 API를 만들어서 옮겨가는 작업이 진행되었습니다. 무사히 개발은 완료되었지만, 개발된 내용을 QA하는 과정에서 일부 테스터 분들에게만 간헐적으로 동일한 내용의 예약이 2개씩 생성되는 문제가 발생했습니다.
한번만 발생되었으면 우연이었거니 했을텐데, 일주일간 랜덤하게 5건 정도 발생했습니다. 게다가 중복 예약이 발생했던 요청내용을 동일하게 만들어서 재현 시도를 하더라도 항상 동일하게 나타나질 않았기 때문에 더 골치가 아팠습니다. 중복 예약이 2개씩 생성되면 결제도 중복으로 발생하게되는데요, 이는 실제 사용자에게 매우 크리티컬한 문제이기 때문에 성급하게 땜빵으로 문제를 해결하기 보다는 정확히 문제 원인을 파악후에 명확한 대책을 세워서 문제를 해결하고자 했습니다.
액세스 로그 확인
먼저 예약 API를 호출한 서버 액세스 로그들 통해서 중복 요청이 어떤식으로 발생했는지 확인해 보았습니다.
gateway(API Gateway), mozart(항공 서버) 의 로그를 확인해본 결과 아래처럼 실제로 예약 API가 1회 호출된 후 정상 응답을 하지 못하고, 1회 재시도한 것은 성공한 액세스 로그가 존재했습니다.
[첫번째 요청(실패)]
2023-06-07 13:45:56.061 [gateway] Init mozart.BookingService/PrepareBookingV2
2023-06-07 13:45:56.081 [mozart] Call started
...(생략)
2023-06-07 13:46:27.408 [mozart] Call finished successfully
2023-06-07 13:46:27.410 [gateway] Response is closed
첫번째 요청의 로그 메시지의 시작과 끝을 보면 31.349초를 기다리다가 Response is closed라고 메시지가 출력되면서 요청이 정상 종료되지 않았습니다. 해당 메시지가 언제 발생하는 것인지 gateway 서버 코드를 살펴보니 통신중이던 TCP 연결이 끊어져서 응답을 보낼 수 없을때 발생하는 오류 메시지였습니다. 연결이 끊어져서 gateway가 클라이언트에서 응답을 보내지는 못했지만, 내부 서버에서는 이미 해당 요청에 대한 처리가 끝나서 예약이 1건 생성된 상태였습니다. “대체 TCP 연결이 왜 끊어졌지? 어떤 상황에서 TCP 연결이 끊어질 수 있는 있는거지?” 라는 질문은 일단 뒤로 하고 재시도 요청에 대한 로그를 마저 살펴보았습니다.
[재시도 요청(성공)]
2023-06-07 13:46:27.070 [gateway] Init mozart.BookingService/PrepareBookingV2
2023-06-07 13:46:27.088 [mozart] Call started
...(생략)
2023-06-07 13:46:56.618 [mozart] Call finished successfully
2023-06-07 13:46:56.620 [gateway] Access finished
두번째 요청의 경우 29.550초 이내로 처리가 완료되었고, TCP 연결이 끊어지지 않고 정상적으로 처리되었습니다. 정상적으로 처리되었으니 추가로 예약이 1건 더 생성되어서 최종적으로 중복 예약이 생성되었습니다.
로그 특이 사항 분석
- 첫번째 요청의 경우 31초 정도 경과되면 TCP 연결이 끊어짐
- 첫번째 요청이 종료된 시간보다 340ms 전에 이미 재시도 요청이 서버에 도착해서 처리가 시작되고있음
중복 예약이 생성된 케이스를 4개정도를 분석해 본 결과 시간의 차이는 조금씩 있지만 위와같은 패턴이 비슷하게 반복되는 것을 확인했습니다.
때문에 요청이 일정시간 이상 지속되면 어디선가 타임아웃이 발생했고, 이로 인해서 재시도가 발생한것이 문제인 것으로 결론을 내린 후 아래 내용 위주로 검토를 해보았습니다.
- 클라이언트 또는 서버에 타임아웃이 몇초로 설정이 되어있는지
- 타임아웃이 발생했을 때 요청을 재시도하는 곳이 있는지
위 사항들을 자세히 분석하기 전에 이해를 돕기 위해 서버 구성이 어떻게 되어있는지를 먼저 소개해보도록 하겠습니다.
카이트/플레이윙즈 서버 구성 소개
카이트/플레이윙즈 서비스 서버들은 MSA(Microservice Architecture) 로 구성되어있고, AWS를 인프라로 사용하고있습니다. 모든 요청은 AWS NLB(Network Load Balancer)를 통해서 쿠버네티스 클러스터의 nginx ingress로 전달되게되고 nginx ingress는 API gateway 서버로 리버스 프록시하는 역할을 하고있습니다. gateway 서버는 내부 서버간 통신에 사용되는 gRPC를 이용하여 요청을 적절한 내부 서버로 전달하게됩니다.
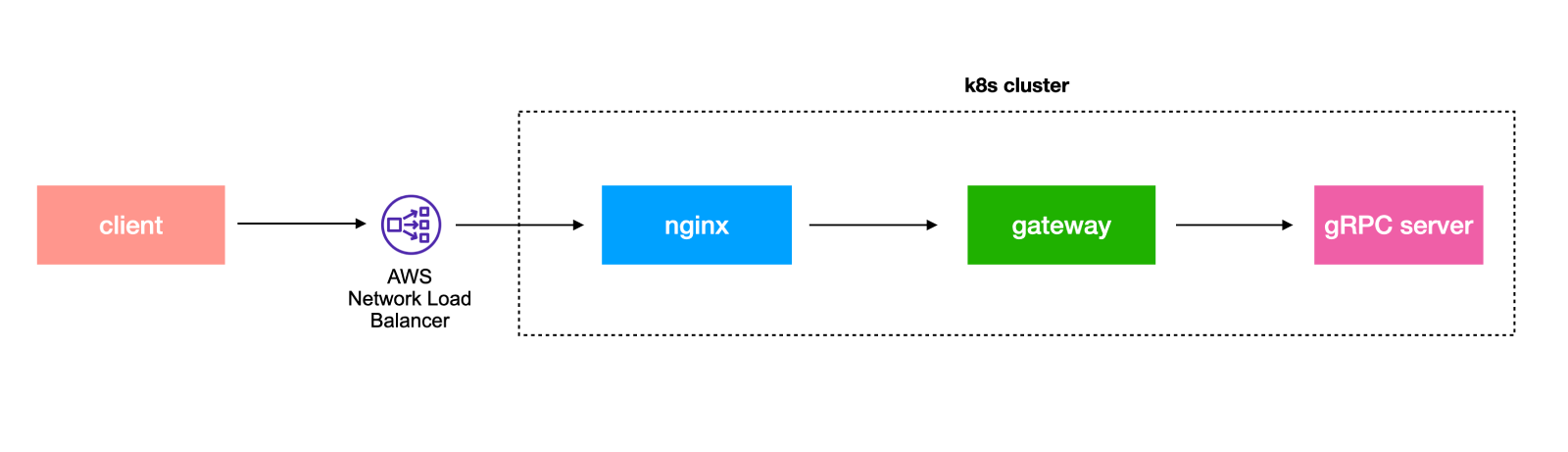
이렇게 놓고보니 단순히 클라이언트와 서버만 확인하면 되는것이 아니고, 하나의 요청을 처리하는데 관여하고있는 다양한 구성요소들 (client, NLB, nginx, gateway, gRPC 서버) 에 대해 각각 점검이 필요해 보였습니다. 단순화 시켜서 보면 요청을보내는 클라이언트가 앱/웹 이고, 해당 요청을 받아서 처리하는 곳이 ‘서버’입니다. 하지만 ‘서버’ 안에서도 앞서 설명한 것 처럼 여러 단계를 거쳐서 요청이 처리 됩니다. 때문에 각 단계의 구성 요소 입장에서 보면 해당 요소가 클라이언트 또는 서버 역할을 모두 하고 있기 때문입니다.
예를들어 리버스 프록시(reverse proxy)로 사용되고있는 nginx의 경우 client로부터 전달된 요청을 받을때는 서버 역할을 수행하지만, 해당 요청을 받아서 gateway로 다시 전달할때는 클라이언트의 역할을 하고있습니다.
결국 이 구성요소들 중 누가 중복 예약을 발생시킨 범인인지 찾아내기 위해서 각 구성 요소들의 타임아웃 설정과, 요청이 실패할 경우 재시도가 수행되는지 여부를 하나씩 확인해 보았습니다.
타임아웃 및 재시도 설정 분석
클라이언트
카이트의 경우 React 기반의 웹앱을 사용하고있기 때문에 테스트시에 웹브라우저를 많이 사용합니다. 이번 중복 예약 생성 오류의 경우에도 크롬이나 웨일 등의 웹브라우저에서 테스트하다가 발견 테스트되었습니다. 단일 브라우저에서만 발생한 것은 아닌걸로 봐서 특정 브라우저로 인해 발생하는 이슈는 아닐거라고 생각했습니다.
그러다보니 가장 처음 의심했던 부분은 역시 클라이언트에서 직접적으로 오류 발생시 재시도를 하고있는지 여부였습니다. 그래서 직접 클라이언트 코드를 살펴봤지만, 명시적으로 재시도하는 코드는 찾을 수 없었고, 클라이언트쪽에서 사용중인 HTTP client 라이브러리인 axios의 코드를 살펴봐도 타임아웃이 발생했을 때 라이브러리 내부적으로 자동 재시도를 수행하는 등의 동작은 확인할 수 없었습니다.
게다가 axios에서 별도의 타임아웃을 설정하지 않았기 때문에 기본값인 0이 사용되고있는 것을 확인했습니다1. 때문에 서버에서 먼저 연결을 끊지 않는 이상 클라이언트에서는 무한히 대기하도록 되어있었습니다.
혹시나 놓친게 있나 싶어서 클라이언트 개발을 리드해주고 계신 종완님께 재확인을 부탁드렸지만 예약 API 호출 관련해서 오류 발생시 명시적인 재시도는 하고있지 않다고 답변을 받았습니다.
추가로 웹브라우저에서 요청이 진행중인 상황에서 새로고침을 하면 기존 진행중인 요청이 취소되면서 서버 로그에 ‘Response is closed’ 메시지가 발생했습니다. 하지만 이는 자동 재시도와는 무관했습니다.
AWS NLB
AWS NLB는 OSI 7계층 중 L4 레벨에서 TCP 또는 UDP 트래픽을 로드밸런싱 해주는 역할을 합니다. 즉 client와 nginx 사이에 NLB를 통해서 TCP 연결이 생성되고, 이후 전송되는 모든 TCP packet 또한 NLB를 통해서 계속 전달됩니다.
NLB는 L4 레벨에서 동작하기 때문에 HTTP 요청 단위의 타임아웃은 당연히 제어가 불가능합니다. 혹시나 싶어서 타임아웃 관련 설정을 찾아보았는데 유휴 연결 타임아웃(connection idle timeout) 은 변경 불가능한 고정값인 350초2 로 되어있는것을 확인했습니다. 이는 특정 TCP 연결이 350초 이상 아무런 패킷을 주고받지 않고 유휴 상태로 있다면 자동으로 해당 연결을 종료시킨다는 의미입니다. 지금 찾고자하는 중복 예약 오류의 경우 타임아웃으로 인한 재시도가 30초 내외의 시간에서 발생했기 때문에 NLB도 용의 선상에서 제외시켰습니다.
nginx
nginx는 HTTP 요청을 수신한 후 IP기반으로 접근제어를 하거나 User-Agent에 따라 추가적인 처리를 한 후 gateway로 보내주는 리버스 프록시(reverse proxy) 역할을 하고있습니다.
nginx가 리버스 프록시 역할을 할 때 클라이언트 쪽과 통신하는 것을 downstream 이라고 부르고, nginx 뒤쪽에 연결된 gateway 와 같은 서버와 통신하는 것을 upstream이라고 지칭합니다. nginx는 이 upstream과 downstream 각각에 대해서 keep-alive 관련 설정과 그 외 타임아웃을 설정하는 것이 가능합니다. keep-alive 란 매번 연결을 맺고 끊느라 성능이 저하되는 현상을 막기 위해서 이미 생성된 연결을 계속 재활용하는 방법입니다.
다음은 저희쪽 서버에서 사용중이던 nginx 설정값 중 일부를 발췌한 값입니다.
- downstream
- keep-alive 관련 설정
keepalive_timeout 75s;keepalive_requests 100;
- keep-alive 관련 설정
- upstream
- keep-alive 관련 설정
keepalive 320;keepalive_time 1h;keepalive_timeout 60s;keepalive_requests 10000;
- 타임아웃 및 재시도 설정
proxy_connect_timeout 5s;proxy_send_timeout 60s;proxy_read_timeout 60s;proxy_next_upstream error timeout;proxy_next_upstream_timeout 0;proxy_next_upstream_tries 3;
- keep-alive 관련 설정
downstream, upstream 모두 여러 타임아웃 설정들이 모두 30초 이상으로 설정되어있어서 문제가 없음을 확인하였습니다. (참고로 proxy_connect_timeout 의 경우에는 연결이 생성되기 까지 걸리는 시간에 대한 타임아웃입니다. 때문에 현재 분석중인 ‘연결된 이후 통신중에 발생한 타임아웃’과는 무관합니다.)
타임아웃 외에도 keepalive_requests 같이 한번 생성된 연결에서 정해진 갯수 이상의 요청을 처리하면 요청을 더이상 재사용하지 않고 닫아버리는 설정도 되어있는 것을 확인할 수 있습니다.
혹시 keep-alive를 통해 연결이 유지되는 동안에는 잘 통신하다가, 설정값에따라 더이상 keep-alive 유지하지 않게 되어 연결이 끊어졌다가 다시 연결을 하는 순간 예상치 못한 오류가 발생하고, 이를 재시도하는 것이 아닐까 의심이 되었습니다. 그래서 keepalive_requests 값을 작게 설정해서 자주 연결이 끊어지게 만들어 두고 직접 테스트를 해보았으나 클라이언트 입장에서 봤을 때 아무 문제 없이 자연스럽게 처리가 되는것을 확인했습니다.
keep-alive 관련 설정에 문제가 없음을 확인한 후에는 리버스 프록시를 수행하는 과정에서 오류 발생시 때 nginx가 자체적으로 해당 요청을 재시도하는 케이스가 있는지에 대해서 살펴보았습니다. 위의 ‘타임아웃 및 재시도 설정’ 에 보면 proxy_next_upstream 설정값이 error, timeout 으로 설정되어있기 때문에 upstream에서 오류 또는 타임아웃이 발생하는 경우 다른 upstream에 자동 재시도를 하게 되는데요, proxy_next_upstream_tries 3; 설정에 의해 최대 3회까지 실제로 재시도가 일어나게됩니다.
예를 들자면 다음과 같은 상황입니다.
- 웹 또는 앱에서는 정확히 1회만 요청
- 해당 요청을 수신한 nginx 가 upstream에 해당 요청을 전달하다가 오류 또는 타임아웃이 발생
- nginx가 해당 오류를 보고 downstream에 오류 응답을 전달하기 전에 등록되어있는 다른 upstream이 존재한다면 해당 upstream으로 요청 재시도
- 재시도한 요청이 성공한 경우 downstream에는 성공 응답을 보냄
client에서는 1회만 요청했지만, nginx에서 gateway(upstream)로 요청을 했다가 타임아웃이 발생하여 재시도를 하게되면 지금 찾고있는 중복 예약 케이스와 일치하는 것이 아닌가? 하고 순간 문제 원인을 찾았다는 기쁨이 몰려오려고 했습니다만, nginx 릴리즈 노트를 보고 기쁨이 훅- 식어버렸습니다.
nginx의 버전별 릴리즈 노트를 살펴보면 2016년 3월 29일에 릴리즈된 1.9.13 버전부터는 POST, LOCK, PATCH 등의 비 멱등 (non-idempotent) 요청의 경우에는 자동 재시도를 하지 않는다고 적혀있었습니다. 해당 버전 이후에는 nginx가 재시도를 하게 하려면 proxy_next_upstream 설정값에 non_idempotent라고 명시적으로 설정을 해줘야한다는 뜻 입니다.
Changes with nginx 1.9.13 29 Mar 2016
*) Change: non-idempotent requests (POST, LOCK, PATCH) are no longer
passed to the next server by default if a request has been sent to a
backend; the "non_idempotent" parameter of the "proxy_next_upstream"
directive explicitly allows retrying such requests.
사용중이던 nginx 버전은 해당 버전보다 훨씬 최신 버전이었고, 예약을 생성하는데 사용했던 API는 POST 방식이었기 때문에 이는 nginx에 의해서 재시도 되지 않았음을 알 수 있었습니다.
(혹시 nginx에 버그가 있을까 싶어서 proxy_read_timeout 을 짧게 설정한 후에 실제로 재시도가 일어나는지 테스트 요청을 해보았으나, POST 요청의 경우 재시도 되지 않았고, GET 요청의 경우 자동 3회 재시도가 일어나는 것을 직접 확인했습니다. nginx는 스펙대로 잘 동작합니다 여러분!)
위와 같은 이유로 결국 nginx도 용의 선상에서 제외시켰습니다.
▶︎ 참고: ‘멱등(idempotent)’ 요청이란 동일 요청을 1번 이상 서버가 처리하더라도 서버 상태가 동일하게 유지되는 요청을 말합니다. 데이터를 생성하거나 변경하는데 사용하는 POST 요청은 일반적으로 멱등 요청이 아닐 가능성이 높습니다. 항공 예약을 생성하는데 사용했던 POST API의 경우에는 동일 요청을 2회 중복 수행하면 동일 내용을 가진 예약이 2개 생성됩니다. 따라서 1회만 수행했을때 예약이 1개만 생성된 서버 상태와 동일하지 않기때문에 이는 멱등 요청이 아닙니다. 반면 서버에 어떤 데이터를 조회하는 GET 요청들은 중복으로 수행해도 서버의 상태가 변경되지 않고 동일한 결과를 얻기 때문에 멱등 요청이라고 볼 수 있습니다. 마지막으로 덧붙이자면 POST요청이라고해서 항상 멱등성을 만족하지 못하는 것은 아니고 상황에 따라 POST 요청도 잘 만들면 멱등성을 만족시키도록 작성하는것이 가능합니다.
gateway & gRPC 서버
국제선 항공 예약 서비스의 경우 Amadeus 또는 Sabre 등의 GDS(Global Distribution System)에서 제공하는 API를 이용하거나, 각 항공사에서 제공하는 API를 통해서 예약을 생성하게됩니다. 특히 GDS에서 제공하는 API의 경우 전체적으로 응답 속도가 매우 느린편이고, 완전한 예약 하나를 생성하기 위해서는 하나의 API호출이 아닌 2-3개 이상의 API를 단계적으로 호출해야하기 때문에 시간이 매우 많이 걸립니다. 그래서 카이트 서버에서도 이러한 API들을 사용하기때문에 API호출에 대한 타임아웃이 넉넉하게 60초로 설정이 되어있습니다.
- 액세스 로그를 봤을때 재시도 상황에서 gateway를 호출한 로그가 별도로 존재하기 때문에, gateway가 아닌 gateway 외부에서 재시도 요청이 수행된 것이 명확함
- gateway내에서도 실패한 gRPC 호출을 자동으로 재시도 하는 코드가 존재하지 않았고, 60초로 설정된 타임아웃이 실제 30초 내외의 시간에서 발생한 타임아웃과 무관함
위 두가지 이유로 gateway와 gateway를 통해 연결되는 내부 gRPC 서버들은 손쉽게 용의 선상에서 제외시켰습니다.
그럼 대체 범인은 누구?
타임아웃 & 재시도를 수행할 수 있는 모든 부분을 검토해봤음에도 도무지 범인을 찾지 못하여 거의 포기를 하려던 차에 종완님이 클라이언트쪽에서 HTTP proxy 도구를 사용해서 비슷한 상황을 재현했다는 희소식을 전해주셨습니다. (종완님 너무너무 감사합니다!!!)
Proxyman은 클라이언트와 서버 사이에 주고받는 HTTP 요청/응답을 손쉽게 모니터링할 수 있고, 요청/응답 내용을 중간에서 조작하는 등의 다양한 작업이 가능해서 개발 생산성을 올려주는 편리한 도구입니다. 종완님이 여기서 제공하는 브레이크 포인트(break point) 기능을 이용해서 나가는 요청에 브레이크 포인트를 걸어서 요청이 서버로 전달되는 것을 막고 타임아웃과 비슷한 상태가 되도록 기다렸더니 다음과 같이 자동으로 재시도하는 요청이 발생하는 것을 재현해 주셨습니다.

놀랍게도 Proxyman쪽에 위와같이 요청이 3개 기록되는 동안 크롬 브라우저의 네트워크 모니터링 탭에는 다음과같이 1개의 요청만이 pending 상태로 계속 진행중인 것을 볼 수 있었습니다. (스크린샷에 포함된 preflight 요청의 경우 실제 요청이 아닌 CORS를 위한 요청 이라 무시해도 좋습니다)
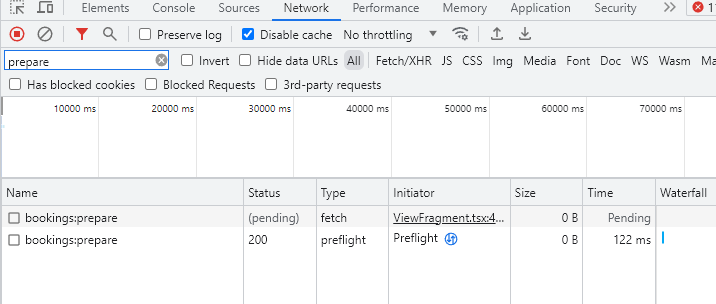
이 결과를 보니 네트워크 연결 상태가 좋지 않을때 몰래 재시도를 수행한 범인은 크롬 브라우저일 확률이 매우 높아졌는데요 진짜 범인을 확인하기 위해 몇가지 의심되던 부분을 마저 확인해 보았습니다.
중복 예약 문제가 발생했던 일부 테스터 분들이 계신 사무실과 카이트 개발팀이 위치한 사무실은 물리적으로 다른곳에 위치해있습니다. 해당 문제가 카이트 개발팀에서는 아무리 재현하려고 해도 재현이 되지 않았는데 테스터 분들이 계신 곳에서는 종종 재현이 되었는데, 카이트 개발팀 쪽에서는 한번도 재현이 되지 않았기 때문에 혹시 사무실 네트워크 설정에 타임아웃 관련 설정이 되어있는게 아닌가 하는 의심을 갖게 되었습니다.
이를 확인하기 위해 예약 API의 응답을 받기까지 무조건 40초가 걸리도록 코드를 수정하여 배포한 후에, 테스터 분들이 계신 사무실과 카이트 개발팀이 위치한 사무실에서 각각 테스트를 진행하였습니다. 예상대로 테스터 분들이 계신 사무실에서는 자동 재시도로 인한 중복 예약이 항상 생성되었고, 카이트 개발팀이 위치한 사무실에서는 해당 문제가 발생하지 않았습니다.
이 결과를 토대로 인프라팀에 문의해본 결과 해당 사무실의 네트워크 보안 솔루션 장비에 30초 타임아웃이 걸려있다는 사실을 확인했고, 인프라팀에서 해당 설정을 조정해주셔서 더이상 동일 문제가 재현되지 않는 것을 확인할 수 있었습니다.
결국 30초 타임아웃이 발생한 원인을 제공한 것은 사무실의 네트워크 보안 솔루션 장비였고, 이렇게 타임아웃이 발생했을 때 암묵적으로 요청 재시도를 수행한 범인은 크롬 브라우저였던 것이 최종적으로 확인되었습니다.
이로써 거의 2주간에 걸쳐서 시간날때마다 들여다보던 문제의 원인을 완전히 파악하는데 성공하여 발을 뻗고 잘 수 있게 되었습니다.
중복 예약 생성 개선
중복 예약이 생성되는 정확한 원인은 파악했지만, 여전히 네트워크 상태가 좋지 않거나 특수한 네트워크에서 예약 생성 API를 호출한다면 중복으로 예약이 생성될 가능성은 여전히 존재합니다. 이를 위해서 예약 생성을 하기 위해 아래처럼 2단계의 과정을 거치는 방식으로 개선할 예정입니다.
- 예약 생성 전에 미리 예약 키(key) 발급 API를 호출하여 예약 키 값을 받아옴
- 기존 예약 생성 API 호출시 1번 단계에서 받아온 키값을 항상 같이 넣어서 전송
이렇게하면 2번 단계에서 재시도로 인한 중복 예약 요청이 들어오더라도 이미 동일 키값으로 생성된 예약이 존재한다면 오류를 발생시키거나, 이미 성공적으로 생성된 예약의 정보를 반환하면서 성공 처리를 할 수 있게 됩니다. 이렇게 만들어진 예약 생성 API는 여러번 호출하더라도 서버의 상태가 동일하게 유지 되기 때문에 POST요청임에도 불구하고 앞서 언급했던 멱등성을 만족한다고 할 수 있습니다.
마무리
예전에는 이런 문제가 발생했을때 로드밸런서와 실제 서버 인스턴스 정도만 확인하면 되서 간단했는데, 최근에는 MSA를 많이 사용함에따라 위에서 살펴본 것 처럼 하나의 요청이 처리되기 까지 관여하는 서버측 요소들이 훨씬 다양해졌습니다. 개별 요소들을 손쉽게 조합하여 독립적으로 개발하고 빠르게 배포할 수 있는 장점이 있지만, 이러한 문제가 발생했을때 문제의 원인을 찾기 위한 트러블슈팅의 난이도가 훨씬 증가한 것 같습니다.
앞서 설명한 환경에서 같이 개발하면서 맞닥뜨리는 문제를 같이 해결해나가고 싶으신 분들은 저희 팀에 많은 지원 부탁드립니다.